Linear Regression is the most basic, and still most useful, tool for analyzing data.
The goal is to find what the relationship between the outcome \(y\) and explanatory variables \(X's\) is.
Say that we start with a very simple “model” that states tries to describe the population function as the following:
\[
y = h(X,\varepsilon)
\]
Here, \(X\) represents a set of observed covariates and \(\varepsilon\) the set of unobserved characteristics, with no no pre-defined relationship between these components.
For now, we will make standard exogeneity assumptions for the identification of the model
Estimation
The functional form is unknowable. However, under the small assumption of Exogeneity of \(X\), we could instead consider the Conditional Expectation function (CEF):
\[
E(y_i|X_i=x) = \int y f_{y|x}(y)dy
\]
This implies a fully non-parametric estimation of the Linear function.
With this, the outcome \(y\) can be decomposed into factors determined by observed characteristics (CEF) and on the error \(\varepsilon\).
\[
y = E(y|X) + \varepsilon
\]
The CEF is a convenient abstract, but to estimate it, we require assumptions. (Recall the assumptions for unbiased OLS?)
Namely, we need to impose a linearity assumption, namely:
frause oaxaca, clearkeepif lnwage !=.mata:y = st_data(.,"lnwage") n = rows(y) x = st_data(.,"female age educ"),J(n,1,1) exx = cross(x,x)/n exy = cross(x,y)/n b = invsym(exx)*exy bend
(Excerpt from the Swiss Labor Market Survey 1998)
(213 observations deleted)
. mata:
------------------------------------------------- mata (type end to exit) -----
: y = st_data(.,"lnwage")
: n = rows(y)
: x = st_data(.,"female age educ"),J(n,1,1)
: exx = cross(x,x)/n
: exy = cross(x,y)/n
: b = invsym(exx)*exy
: b
1
+---------------+
1 | -.145393595 |
2 | .0161424301 |
3 | .0719321873 |
4 | 1.970020725 |
+---------------+
: end
-------------------------------------------------------------------------------
.
Here \(\varepsilon\) is the true population error. \(\hat\beta\) is unbiased if the second term has an expectation of Zero. (the error is independent from \(X\)).
The first term is assumed fixed \(E(X_i X_i')\). And, because \(E(X_i\varepsilon)=0\), and \(\frac{1}{\sqrt N} \sum(X_i\varepsilon)\) is normalized, by CLT we have that:
In other words, the variance of \(\hat\beta\) allows for arbitrary relationship among the errors, as well as heteroskedasticity. This, however is impossible to estimate!, thus we require assumptions
Homoskedasticity and independent samples
With homoskedastic errors \(\sigma^2 = \sigma_i^2 \ \forall i \in 1,...,N\) .
But, \(\sigma^2\) is not known, so we have to use \(\hat\sigma^2\) instead, which depends on the sample residuals: \[
\hat\sigma^2 = \frac{1}{N-k-1}\sum \hat e^2
\]
Where we account for the fact true errors are not observed, but rather residuals are estimated, adjusting the degrees of freedom.
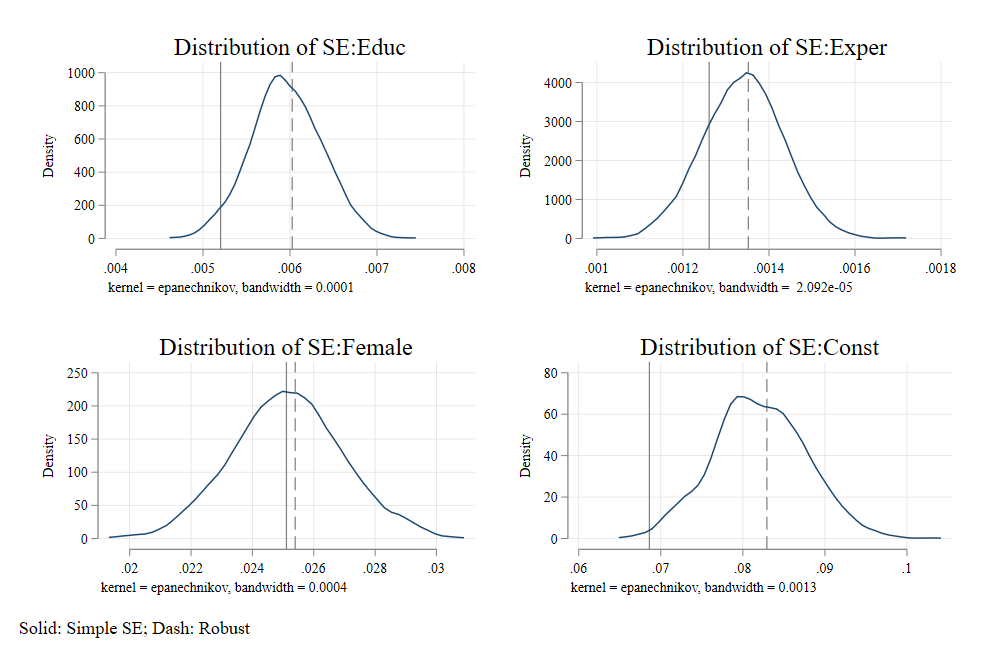
Which imposes NO penalty to the fact that we are using residuals not errors. If we account for that however, we obtain what is known as HC1, SE, the standard in Stata. (when you type robust)
A residual is model dependent, and should not be confused with the model error \(\hat \varepsilon \neq \varepsilon\). Because of this, additional corrections are needed to obtained unbiased \(var(\hat\beta)\) estimates. (Degrees of freedom). But other options exists.
That way, Heteroskedasticity is addressed, but without changing the model estimates \(\beta's\)
Lifting Even more Assumptions: Correlation
One assumption we barely consider last semester was the possibility that errors could be correlated across observations. (except for time series and serial correlation)
For example, families may share similar unobserved factors, So would people interviewed from the same classroom, cohort, city, etc. There could be many dimensions to consider possible correlations!
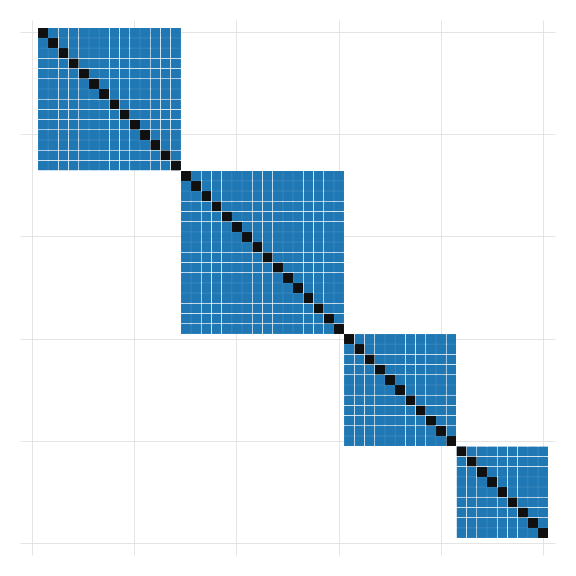
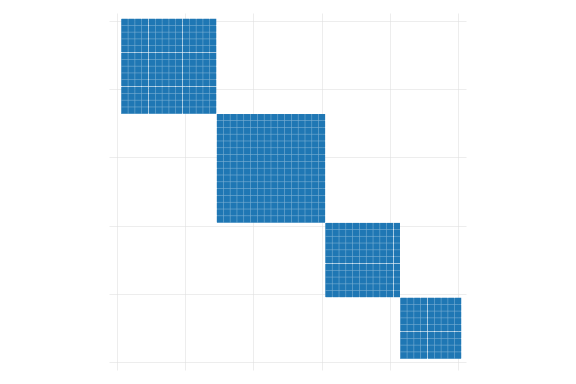
In that situation, we may be missmeasuring the magnitude of the errors (probably downward), because the \(\Omega\) is no longer diagonal: \(\sigma_{ij} \neq 0\) for some \(i\neq j\).
But, estimate all parameters in an NxN matrix is unfeasible. We need assumptions!
New Assumptions
Say we have \(G\) groups \(g=(1…G)\) . We can rewrite the expression for \(\hat\beta\) as follows:
We can assume that individuals are correlated within groups \(E(s_g's_g) =\Sigma_g\) , but they are uncorrelated across groups \(E(s_g s_g')=0 \ \forall \ g \neq g'\) .
These groups are typically known as “clusters”
Addressing Correlation
The idea of correcting for clusters is pretty simple. We just need to come up with an estimator for \(\Sigma_g\) for every cluster, so that:
Here \(\Omega_g\) should be an approximation of the variance covariance matrix among the errors of ALL individuals that belong to the same cluster. But how do we approximate it?
As with the EW - HC standard errors, there are many ways to estimate Clustered Standard errors. See MacKinnon et al (2023) for reference. We will refer only to the simpler ones CV0 and CV1.
Recall we approximate \(\sigma^2_i\) with \(\varepsilon_i^2\). Then we can approximate \(\sigma_{ij}\) with \(\varepsilon_j \varepsilon_i\). More specifically:
Similar to HC. CV0 does not correct for degrees of freedom. CV1, however, accounts for Degrees of freedom in the model, and clusters.
Code
sort iscomata:// 1st Sort Data (easier in Stata rather than Mata) and reloady = st_data(.,"lnwage") x = st_data(.,"educ exper female"),J(1434,1,1) cvar= st_data(.,"isco") ixx = invsym(cross(x,x)); xy = cross(x,y) b = ixx * xye = y:-x*b// Set the panel info info = panelsetup(cvar,1); g=rows(info); n=rows(y)// get X_g'e for all groups: s_xg_e = panelsum(x:*e,info)// Sum Sigma_g sigma_g = s_xg_e's_xg_e cv0 = ixx*sigma_g*ixx cv1 =g/(g-1)*(n-1)/(n-k)*ixx*sigma_g*ixx b,sqrt(diagonal(cv0)),sqrt(diagonal(cv1))end
two (scatter rr11 rr12 if rr13==1, ms(s) msize(2.1)) /// , aspect(1) legend(off) xtitle("") ytitle("") yscale(off) xscale(off) name(m1, replace)
Code
two (scatter rr11 rr12 if rr14==1, ms(s) msize(2.1)) /// , aspect(1) legend(off) xtitle("") ytitle("") yscale(off) xscale(off) name(m2, replace)
Code
two (scatter rr11 rr12 if rr14==1 | rr13==1, ms(s) msize(2.1)) /// , aspect(1) legend(off) xtitle("") ytitle("") yscale(off) xscale(off) name(m3, replace)
Beware of over-clustering
While clustering helps address a problem of “intragroup” correlation, it can/should be done with care. It is important to be aware about some unintended problems of over-clustering.
CV0 and CV1 work well when you have a large number of Clusters. How many? MHE(2009) says…42 (this is like having large enough samples for Asymptotic variance). If # clusters are small, you would do better with other approaches (including CV2 and CV3).
When you cluster your standard errors, you will “most-likely” generate larger standard errors in your model. Standard recommendation (MHE) is to cluster at the level that makes sense (based on data) and produces largest SE (to be conservative).
Role of clusters
Standard Errors
You may also consider that clustering does not work well when sample sizes within cluster are to diverse (micro vs macro clusters)
And there is the case where clustering is required among multiple dimensions (see vcemway). Where the unobserved correlation could be present in different dimensions.
So what to cluster and how?
Mackinnon et al (2023) provides a guide on how and when to cluster your standard errors. (some are quite advanced)
General practice, At least use Robust SE (HC2 or HC3 if sample is small), but use clustered SE for robustness.
You may want to cluster SE based on some theoretical expectations. Choose -broader- groups for conservative analysis.
In treatment-causal effect analysis, you may want to cluster at the “treatment” level.
But…Beyond hc0/1 and CV0/1 there is not much out there for correcting Standard errors in nonlinear models.
The Bootstrap
If you can’t Sandwich 🥪, you can re-Sample
The discussion above refered to the estimation of SE using \(Math\). In other words, it was based on the asymptotic properties of the data. Which may not work in small samples.
An alternative, often used by practitioners, is using re-sampling methods to obtain approximations to the coefficient distributions of interest.
But… How does it work?🤔
First ask yourself, how does Asymptotic theory work (and econometrics)? 😱
Note: I recommend reading the -simulation- chapter in The effect, and simulation methods chapter in CT.
A Brief Review…again 😇
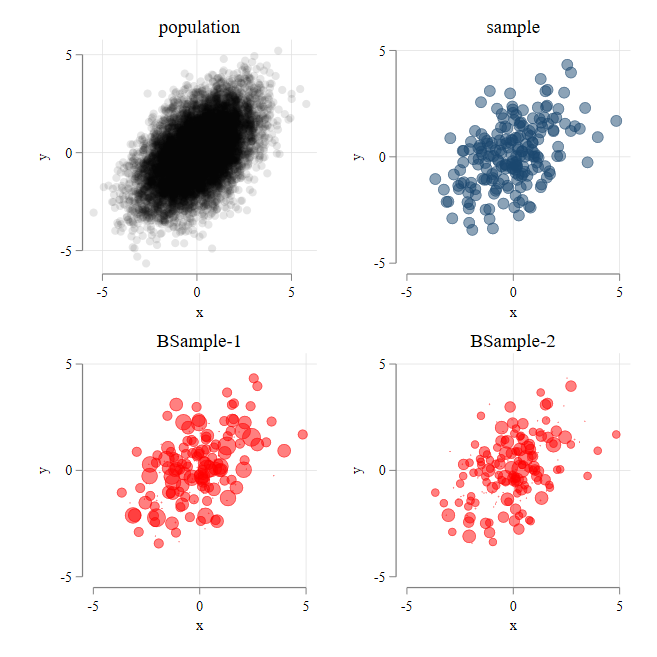
If I were to summarize most of the methodologies (ok all) we used last semester, and this one, the properties that have been derived and proofed are based on the assumption that we “could” always get more data (frequentist approach).
There is population (or super population) from where we can get samples of data (and never repeat data).
We get a sample (\(y,X\)) (of size N)
Estimate our model : method(\(y,X\))\(\rightarrow\)\(\beta's\)
Repeat to infinitum
Collect all \(\beta's\) and summarize. (Mean and Standard deviations)
Done.
The distributions you get from the above exercise should be the same as what your estimation method produces. (in average) (if not, there there is something wrong with the estimation method)
But we only get 1 Sample!
The truth is we do not have access to multiple samples. Getting more data, is in fact, very expensive. So what to do ?
Rely on Asymptotic theory
learn Bayesian Econometrics 🥺
or-resample? and do Bootstrap!
Basic idea of Bootstrapping
In the ideal scenario, you get multiple samples from your population, Estimate parameters, and done.
If not possible you do the next best thing. You get your sample (assume is your mini-population),
Draw subsamples of same size (with replacement) (\(y_i^s,X_i^s\))
estimate your model and obtain parameters \(\beta^s_i\)
Summarize those parameters…and done, you get \(Var(\hat\beta)\) for 🆓. (or is it?)
Bootstrapping
👢Bootstrapping is a methodology that allows you to obtain empirical estimations of standard errors making use of the data in hand, and without even knowing about Asymptotic theory (other than how to get means and variances).
Bootstrap Sample
And of course, it comes in different flavors.
Standard Bootstrap:
Non-parametric Bootstrap: You draw subsamples from the main sample. Each observation has the same pr of being selected.
Easiest to implement ( see bootstrap:)
Works in almost all cases, but you may have situations when some covariates are rare.
Can allow for “clusters” using “block bootstrapping”.
Standard Bootstrap:
Parametric Bootstrap: You estimate your model, make assumptions of your model error.
You need to implement it on your own. \(y^s=x\hat b+\tilde e\) for \(\tilde e \sim f(\hat \theta)\)
It will not work well if the assumptions of the error modeling are wrong.
Standard Bootstrap:
Residual bootstrap: Estimate your model, obtain residuals. Re-sample residuals
Again, implement it on your own. \(y^s = x\hat b+\tilde e\) for \(\tilde e \sim {\hat e_1 , ... , \hat e_N}\)
It depends even more on the assumptions of the error modeling.
Wild Bootstrap
Then there are the more advanced (but faster) Bootstrap methods: WildBootstrap
UWild bootstrap: Estimate your model, obtain residuals, and re-sample residual weights.
Again…on your own: \(y^s = x\hat b +\hat e * v\) , where \(v \sim ff()\) where \(ff()\) is a “good” distribution function. \(E(v)=0 \ \& \ Var(v)=1\)
Re-estimate the model and obtain \(\hat \beta's\). Repeat and summarize.
Actually quite flexible, and works well under heteroskedasticity!
It can also allow clustered standard errors. The error \(v\) no longer changes by individual, but by group. It also works well with weights.
Wild Bootstrap:
UWild bootstrap-2 : Estimate your model, obtain Influence functions 😱 , and re-sample residual weights.
This is an extension to the previous option. But with advantages
you do not need to re-estimate the model. Just look into how the the mean of IF’s change.
it can be applied to linear and nonlinear model (if you know how to build the IF’s)
Works well with clustered and weights.
Wild Bootstrap:
CWild bootstrap: Similar UWild Bootstrap, Obtain Influence functions under the Null (imposing restrictions), and use that to test the NULL.
No, you do not need to do it on your own. see bootest in Stata.
Works pretty well with small samples and small # clusters. Probably the way to go if you really care about Standard errors.
How to Bootstrap? in Stata
I have a few notes on Bootstrapping here Bootstrapping in Stata. But let me give you the highlights for the most general case.
Most (if not all commands) in Stata allow you to obtain bootstrap standard errors, by default. see:help [cmd]
This last command may allow you to bootstrap multiple models at the same time, although it does require a bit of programming. (and a do file)
Code
frause oaxaca, cleargen tchild = kids6 + kids714captureprogramdrop bs_wages_childrenprogram bs_wages_children, eclass// eclass is for things like equations ** Estimate first modelreg lnwage educ exper femalematrix b1 = e(b)matrixcoleq b1 = lnwage ** Estimate second modelreg tchild educ exper femalematrix b2 = e(b)matrixcoleq b2 = tchild ** Put things together and postmatrix b = b1 , b2ereturnpost bendbootstrap: bs_wages_children
(Excerpt from the Swiss Labor Market Survey 1998)
(running bs_wages_children on estimation sample)
warning: bs_wages_children does not set e(sample), so no observations will be
excluded from the resampling because of missing values or other
reasons. To exclude observations, press Break, save the data, drop
any observations that are to be excluded, and rerun bootstrap.
Bootstrap replications (50): .........10.........20.........30.........40......
> ...50 done
Bootstrap results Number of obs = 1,647
Replications = 50
------------------------------------------------------------------------------
| Observed Bootstrap Normal-based
| coefficient std. err. z P>|z| [95% conf. interval]
-------------+----------------------------------------------------------------
lnwage |
educ | .0858252 .0062606 13.71 0.000 .0735547 .0980957
exper | .0147343 .001283 11.48 0.000 .0122196 .017249
female | -.0949227 .0305222 -3.11 0.002 -.1547452 -.0351003
_cons | 2.21885 .0855954 25.92 0.000 2.051086 2.386614
-------------+----------------------------------------------------------------
tchild |
educ | .0177854 .0087606 2.03 0.042 .000615 .0349558
exper | -.0047747 .0017462 -2.73 0.006 -.0081972 -.0013522
female | -.1306332 .0395711 -3.30 0.001 -.2081911 -.0530753
_cons | .4163459 .1201824 3.46 0.001 .1807927 .6518991
------------------------------------------------------------------------------
Why does it matter? because you may want to test coefficients individually, or across models. This is only possible if the FULL system is estimated jointly
What about Wild Bootstrap?
Wildbootstrap is available using boottest (ssc install bootest)
And in Stata18+, you have wildbootstrap (although is meant for clustered SE)
So bootstrap (and its many flavors) are convenient approaches to estimate standard errors and elaborate statistical Inference, but its not infallible.
If the re-sampling process does not simulate the true sampling design, we may miss important information when constructing SE.
When the parameters are estimated using “hard” cutoffs or restricted distributions, it may not produce good approximations for SE.
You usually require MANY repetitions (standard = 50, but you probably want 999 or more). The more the better, but has some computational costs. (specially simple bs)
Some methods play better with weighted samples, clusters, and other survey designs than others. And some require more know-how than others.
So choose your 🔫weapon wisely!
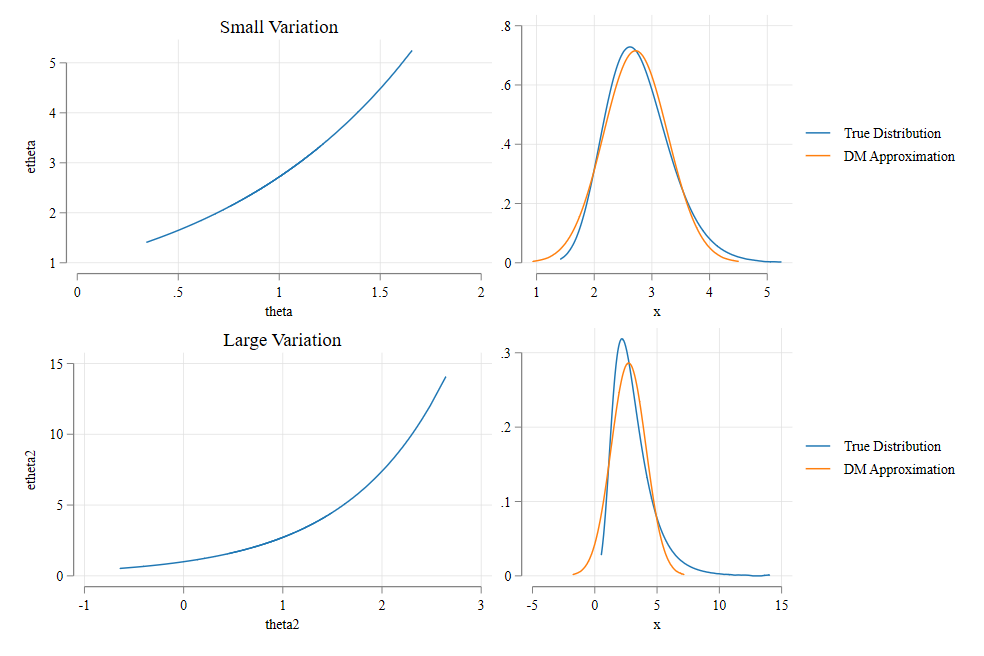
Small Diversion 🦌: The Delta Method
Variance of nonlinear functions
Some times (perhaps not with simple OLS) you many need to estimate Standard errors for transformations of your main coefficient of interest, or combinations of those coefficients.
Say that you estimated \(\theta \sim N(\mu_\theta, \sigma^2_\theta)\) but are interested in the distribution of \(g(\theta)\). How do you do this?
Two options:
you re estimate \(g(\theta\)) instead, or
you make an approximation, using the Delta Method
How does it work?
The Delta method uses the linear approximations to approximate the otherwise not known distributions.
Further, It relies on the fact that linear transformations a normal distribution, is on itself normal. For example:
What happens when you add too many variables in a model?
Increase Multicolinearity and coefficient variance (too much noise)
R2 overly large (without explaining much)
Far more difficult to interpret (too many factors)
May introduce endogeneity (when it wasnt a problem before)
How can you solve the problem?
You select only a few of the variables, based on theory, and contribution to the model
What if you can’t choose?
ML: We let the 💻Choose for you
Before we start. The methodology we will discuss are usually meant to get models with “good” predictive power, and some times better interpretability, not so much stat-inference (although its possible)
When you do not know how to choose, you could try select a subset of variables from your model such that you maximize out-of-sample predictive power
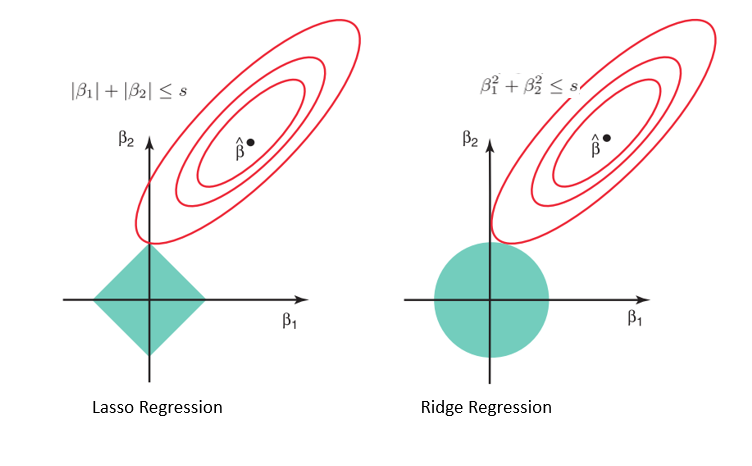
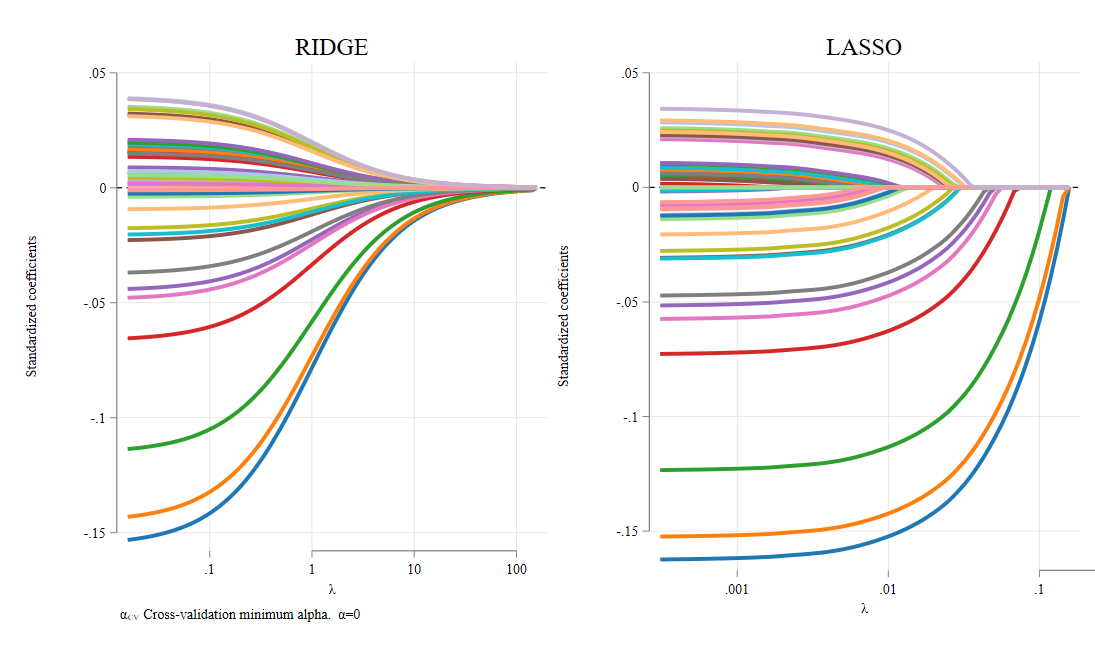
This essentially aims to find parameters that reduces SSR, but also “controls” for how large \(\beta's\) can be, using a shrinkage penalty that depends on \(\lambda\).
If \(\lambda = 0\) you get Standard OLS, and if \(\lambda \rightarrow \infty\) , you get a situation where all betas (but the constant) are zero. For intermediate values, you may have better models than OLS, because you can balance Bias (when \(\beta's\) are zero) with increase variance (when all \(\beta's\) vary as they “please”)
We usually start with Ridge, because is relatively Easy to implement, since it has a close form Solution:
\[
\beta = (X'X + \lambda I)^{-1}{X'y}
\]
Code
setlinesize 255frause oaxaca, clearkeepif lnwage!=.gen male = 1-femalemata:y = st_data(.,"lnwage") x = st_data(.,"educ exper female male")// Standardization. Need men and SD mn_x = mean(x) sd_x = diagonal(sqrt(variance(x)))'// Centering and addinc constant x = (x:-mn_x):/sd_x; x = x,J(1434,1,1) i0 = I(5);i0[5,5]=0// SD errors as Column, including a 1 for Constant sd_x=sd_x'\1 xx = (cross(x,x)) ; xy = (cross(x,y)) bb0 = invsym(xx)*xy bb1 = invsym(xx:+i0*1)*xy bb10 = invsym(xx:+i0*10)*xy bb100 = invsym(xx:+i0*100)*xy bb1000 = invsym(xx:+i0*1000)*xy bb10000 = invsym(xx:+i0*10000)*xy bb100000 = invsym(xx:+i0*100000)*xy// bb0:/sd_x,bb1:/sd_x,bb10:/sd_x,bb100:/sd_x,bb1000:/sd_x,bb10000:/sd_x, bb100000:/sd_xend
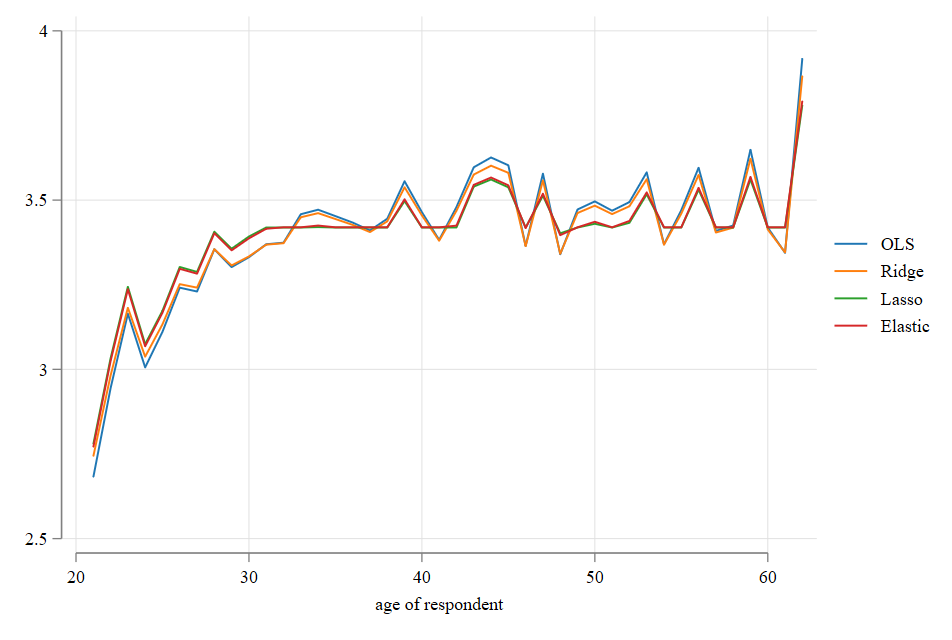
Ridge is a relatively easy model to understand and estimate, since it has a close form solution. It has the slight disadvantage that you still estimate a coefficient for “every” variable (tho some are very small)
Another approach, that overcomes this advantage is known as Lasso.