Then just compare the outcomes: The read Pill Saved the world.
Thus, treatment effect is simply the difference in the potential outcomes: Two counterfactuals!
This difference captures the TRUE treatment effect. Easy enough…
The Path not taken
The way we express the \(TE_i\), compares counterfactuals. Two possible States of the world, where an allknowing researcher can perfectly identify TE.
Unfortunately, the same person cannot take both paths, and we cannot see both options. A person is either Treated or Untreated. Thus, the first approach to Casual effects is impossible.
…
But it does provide us with a clue of how to go ahead and analyze Causal effects. We “simply” need to estimate the counterfactual!
But before going deeper into how to estimate the counterfactuals And treatment effects some notation
Potential Outcomes: Notation
\(i\) will represent a unit. Person, city, country, school, classroom, etc
\(D\) will indicate the treatment Status of a unit. \(D=1\) means is treated, and \(D=0\) is untreated.
Each unit has two potential outcomes \(Y_i(D=1)\) and \(Y_i(D=0)\)
All units have only one effective or realized outcome: \(Y_i\), which is what we observe, and depends on their treatment status:
\[Y_i=(1-D_i)*Y_i(0)+D_i*Y_i(1)\]
Unit Specific causal effect is the difference between potential outcomes: \[\delta_i = Y_i(1)-Y_i(0)\]
\(\pi\) is the proportion of treated units
Parameters of Interest
Assume we can see the true USCE (unit specific casual effect) for all units. In addition to their Treatment Status.
There are three parameters one might be interested in analyzing:
\[
\begin{aligned}
ATE &= E(\delta_i) \\
ATT &= E(\delta_i|D_i=1) \\
ATU &= E(\delta_i|D_i=0)
\end{aligned}
\]
In general, this three estimands may tell very different stories.
Lets Put some numbers here
Simulating effects Stata
Code
clearsetlinesize 255setseed 101setobs 1000gen y0 = rnormal(5)gen t = rnormal(0.0,0.5)gen y1 = y0+t** Assume only those with t>0 take treatmentgen trt =(t>0)geny = y0 * (1-trt) + y1 * (trt)format y0 y1 y t %4.3f listin 1/10, sep(0) clean** For Everyone 100 obstabstat t, by(trt)
Number of observations (_N) was 0, now 1,000.
y0 t y1 trt y
1. 5.254 -0.801 4.453 0 5.254
2. 4.997 0.039 5.035 1 5.035
3. 2.608 -0.490 2.118 0 2.608
4. 6.280 -0.579 5.700 0 6.280
5. 5.761 0.090 5.850 1 5.850
6. 6.132 0.211 6.342 1 6.342
7. 4.928 0.153 5.081 1 5.081
8. 4.377 -0.073 4.304 0 4.377
9. 3.142 0.427 3.569 1 3.569
10. 6.050 -0.332 5.718 0 6.050
Summary for variables: t
Group variable: trt
trt | Mean
---------+----------
0 | -.3984745
1 | .3748617
---------+----------
Total | -.0187664
--------------------
But there is only 1
But, we never see potential outcomes, nor unit specific effects.
The most naive estimator is to just estimate the mean difference in “post-treatment” outcome after treatment was in place. But that would be very biased!
Code
gen yy0 = yif trt==0gen yy1 = yif trt==1listy yy1 yy0 trt in 1/10regy trt
This is a strong assumption that is still required to estimate of treatment effects.
It assumes that:
Treatment is Homogenous. Same intensity, quality, type of treatment among all treated.
There are no spill overs. Your Treatment Status effects you and you only, and you are only affected by your treatment status. No externalities nor Spillovers.
Also, there are no general equibrium effects
And NO Anticipation.
This assumptions namely guaranties that when a unit is not treated, its/his/her outcome will not change.
Narrowing down the problem
Individual level effects are impossible to identify. We only observe one outcome at a time. (not both)
It is possible to identify causal effects on groups (treated, not-treated, kind-of-treated). But..
Simple Mean difference will not identify causal effects, unless Independence and Sutva assumptions hold
This however, suggests a path. Constructing good counterfactuals can help idenfiying the Causal effects.
Goal:
Identify a control/comparison group that is statistically identical to the treated group, except for the Treatment Status
The Gold Standard: Randomized Control Trials
To keep in mind
Searching for good controls doesnt require having access to perfect “clones”. However, in average, we need groups (T vs UT) that are very similar to each other.
In general, research designed is guided by the rules of program or treatment assignment on participants.
When researchers have control on the assingment rules, the best approach is to design a randomized control trial.
In an RCT, randomized assigment, eliminates any selection-bias problems (although SUTVA remains as an assumption)
RCT and Selection Problems
Consider the example of the Health Impacts of Hospitals.
Hospitals (or health care) should improve health of individuals. but
Only unhealthy people will use Health care services. Selection bias
Thus It may look that Hospitals Hurt people’s health becuase those who used it have lower health than those who dont: \[
E(Y|D=1)-E(Y|D=0) = ATT + E(Y(0)|D=1)-E(Y(0)|D=0)
\]
So even if Health services help those in need (ATT). If the selection bias is large, Naive estimations may suggest Hospitals are harmful.
This is a problem caused because Treatment(going to the Hospital) is affected by pre-conditions or potential treatment outcomes.
Under Random assigment, and SUTVA, this can be fixed:
If assigment is given as a lottery, potential benefits (Treatment effects) will not be affected by the lottery.
Here, ATT will be the same as ATU. which will allow us to estimte ATE as: \[
\begin{aligned}
ATE &= E(Y|D=1)-E(Y|D=0) \\
&= E(Y|D=1)-E(Y(0)|D=1) \\
&= E(Y(1)|D=0)-E(Y|D=0) \\
\end{aligned}
\]
Stata Example
Code
gen trt2=rnormal()>0gen yrct = y0 * (1-trt2) + y1 * (trt2)tabstat t y0 y1 yrct, by(trt2)reg yrct trt2
Summary statistics: Mean
Group variable: trt2
trt2 | t y0 y1 yrct
---------+----------------------------------------
0 | -.0097507 5.061626 5.051875 5.061626
1 | -.027891 4.984309 4.956418 4.956418
---------+----------------------------------------
Total | -.0187664 5.023199 5.004433 5.009338
--------------------------------------------------
Source | SS df MS Number of obs = 1,000
-------------+---------------------------------- F(1, 998) = 2.64
Model | 2.76706003 1 2.76706003 Prob > F = 0.1046
Residual | 1046.22695 998 1.0483236 R-squared = 0.0026
-------------+---------------------------------- Adj R-squared = 0.0016
Total | 1048.99401 999 1.05004406 Root MSE = 1.0239
------------------------------------------------------------------------------
yrct | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
trt2 | -.1052076 .0647568 -1.62 0.105 -.2322827 .0218675
_cons | 5.061626 .0456524 110.87 0.000 4.97204 5.151212
------------------------------------------------------------------------------
Internal vs External Validity
RCTs are not the only strategy that allows you to control the Rules of Treatment. In Experimental Economics this is done quite often
you select your sample (of students), and randomly assigned treatments of interest (Experimental design).
There are, however, further considerations to be taken:
Internal Validity
The estimated Impact is net of all other confunding factors (Random assigment)
External Validity
The estimated impact can be generalized to the population in general. (Random Sample)
How to Randomize
Depends mostly on how reasonable is to mantain SUTVA assumption
Examples
CCT and Education in Mexico
Progresa/Prospera is a CCT program for poor mothers based on children school enrollment to suport education attainment.
Eligibility was based on Census data on Poverty levels and Baseline Data collection. But during phase-in period, only 2/3 if localities were selected to receive the Transfer
Water and Sanitation Intervention in Bolivia
In 2012 IADB and Bolivian Goverment implemented a random assigment of water/sanitation interventions in Small Rural Communities.
From 369 eliginle communities, 182 were selected at random for the program implementation, via public lotteries, constraining on Community Size
How to Analyze the Data
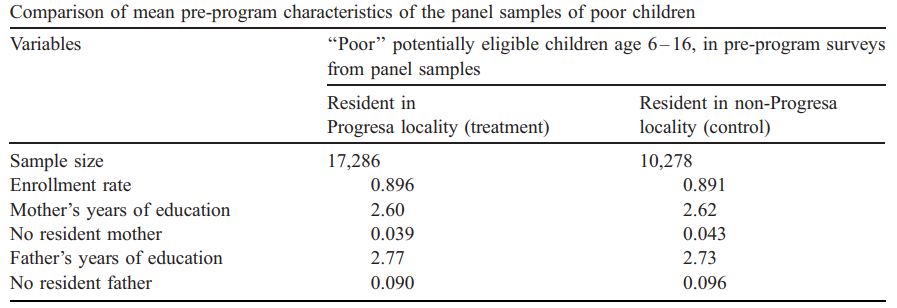
Verify Data Balance: Even if treatment was assigned at random, it is important to verify of groups remain comparable. (Thus avoid compossition effects)
Mean Difference: Because of Random Assigment, one could use simple mean differences to estimate ATE
Consider using controls: Under RA, controls will not affect the outcome, but may improve precision: \(y_i = \alpha_0 + \tau D_i + x_i\beta + \varepsilon_i\).
But controls should not be affected by the treatment itself (thus should be pre-treatment)
May consider falsification tests
And Other Robustness test: Outliers, or distributional impacts may be of interest
Example
School subsidies for the poor:
Evaluating the Mexican Progresa poverty program
Paul Schultz (2004)
Background
Progresa is a Cash Transfer Program designed to increase School Enrollment among the poor, minimizing desincentives to work.
This program provided Grants to families whos children attended school for atleast 85% of the school year, covering between 50/75% of school cost.
While there were 495 localities that were eligible to benefit from the program, only 314 were randomly selected to start reciving resources for the first 2 years. With the unselected localities being treated a couple of years later.
The program continued beyond the original scope of the policy, now its known as Progresa/Oportunidades
Method
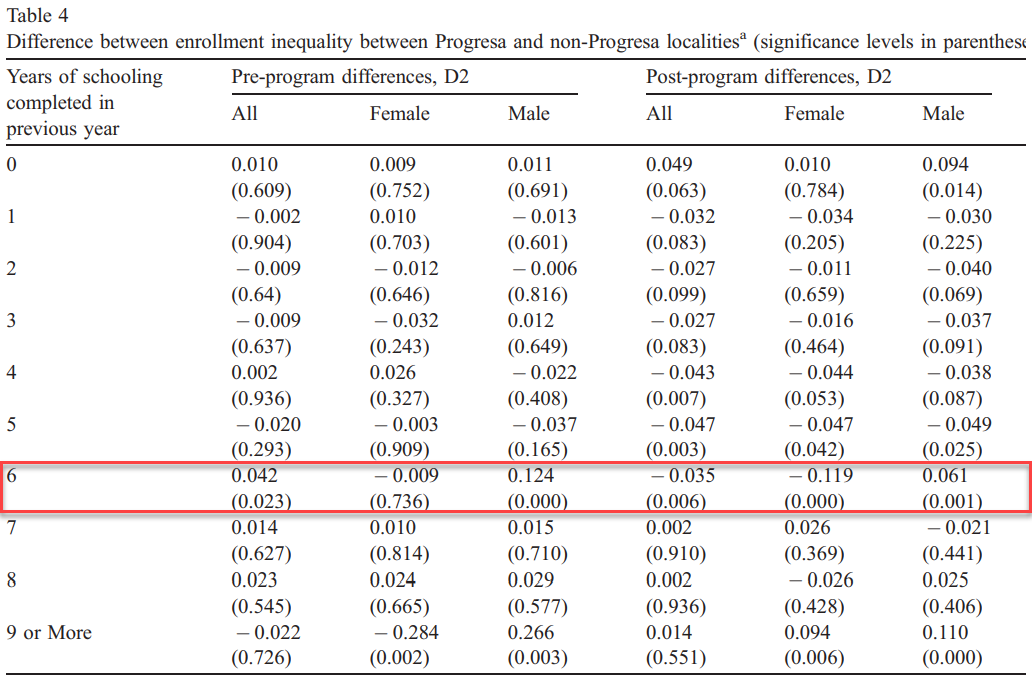
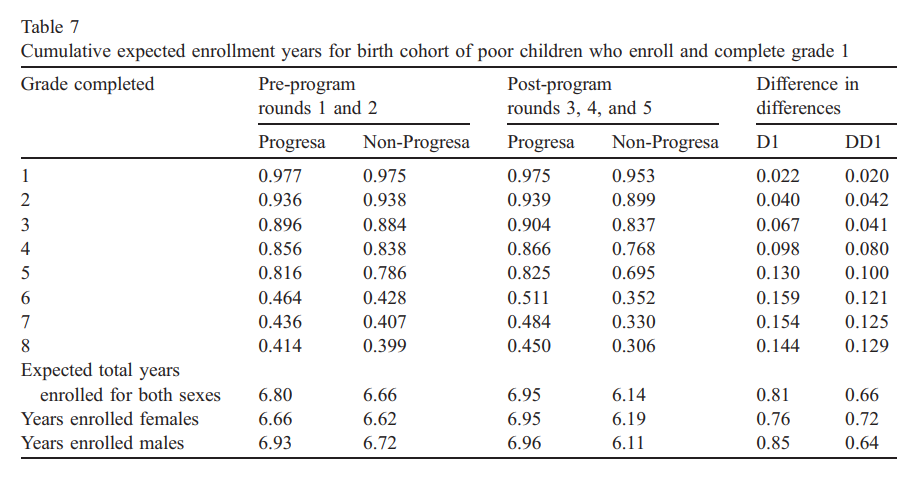
Goal. Estimate the impact of Progresa (P) on Enrollment (S) \[
S_i = a_0 +a_1 P_i + a_2 E_i + a_3 P_iE_i + \delta Enrolled_c + \beta X + e_i
\]
\(P_i=1\) if the comunity is eligible
\(E_i=1\) if the child is Poor
\(P_i * E_i\) the impact on Poor Chilren in eligible communities.
Model can be estimated Separately (5 years), or using pooled data
This is a kind of DIDID model. However, we could consider it as a simple mean comparison between those Effectively treated and those untreated.