In the ideal world, where we can see all possible outcomes and scenarios of your potential treatments, it will be very simple to estimate treatment effects:
\[
\delta_i = Y_i(1)-Y_i(0)
\]
This works because all observed and unobserved individual characteristics are kept fixed, except for the treatment Status.
\[y_i(D)=y_i(X,u,D)\]
So when comparing a person with himself (clones or parallel worlds), we know (or at least expect) that everything else is the same, and that differences between the two states are explained only by the treatment.
The Problem
We do not observe both ALL States at the same time. People will either be treated or untreated, not both.
So what can we do?
We need to find good counterfactuals!
This means finding people are very similar to the ones treated, so they can be used as the examples of the “what if” question.
But there is a problem. Even in the best scenarios, we can never be asure about how to control for unobservables…or can we?
You can always RCT But it can be expensive
You can IV the problem but its hard to justify
You can add FE, but you have time varying errors
Then what?
You could RDD the problem (if you have the right data!)
What is RDD?
RDD or Regression Discontinuity design is methodology that is known for its clean identification and with a relatively easy visualization tool to understand the identification, and solve the problem of unobserved distributions. (see here for a recent paper on how to make graphs on this).
In fact, the treatment Status has a very clear Rule!
Consider the following problem:
You want to study the role of college on earnings.
You have data on people who are applying to go to school. They all take some standardized tests. Their grade will determine if they get into College or not.
People with high skills will get a higher grades in the GRE, go to college, and probably get higher salaries.
But, there is a problem. How can you figure out if wages are due to College or skill?
Possible Solution
Say that we actually have access to the grades, which range from 100 to 200. And assume that you say, every one with grades higher than 170 will go to college.
Can you estimate the effect now?
You can’t compare people with more than 170 to those with less than 170. Because skill or ability will be different across groups.
However, what if you compare individuals with 170-172 vs 167-169?
These individuals are so close togeter they problably have very similar characteristics as well!
you have a Localized randomization.
In this case, your analysis is those individuals just above the thresholds to those just below (counterfactual)
Unless you think grades near the threshold are as good as random, then you have a design to identify treatment effects!
RDD: How it works.
Selection and Index:
The first thing you need to see if you can use and RDD is to see if you have access to a variable that “ranks” units.
This variable should be smooth and preferibly continuous.
age, distance from boarder, test score, poverty index
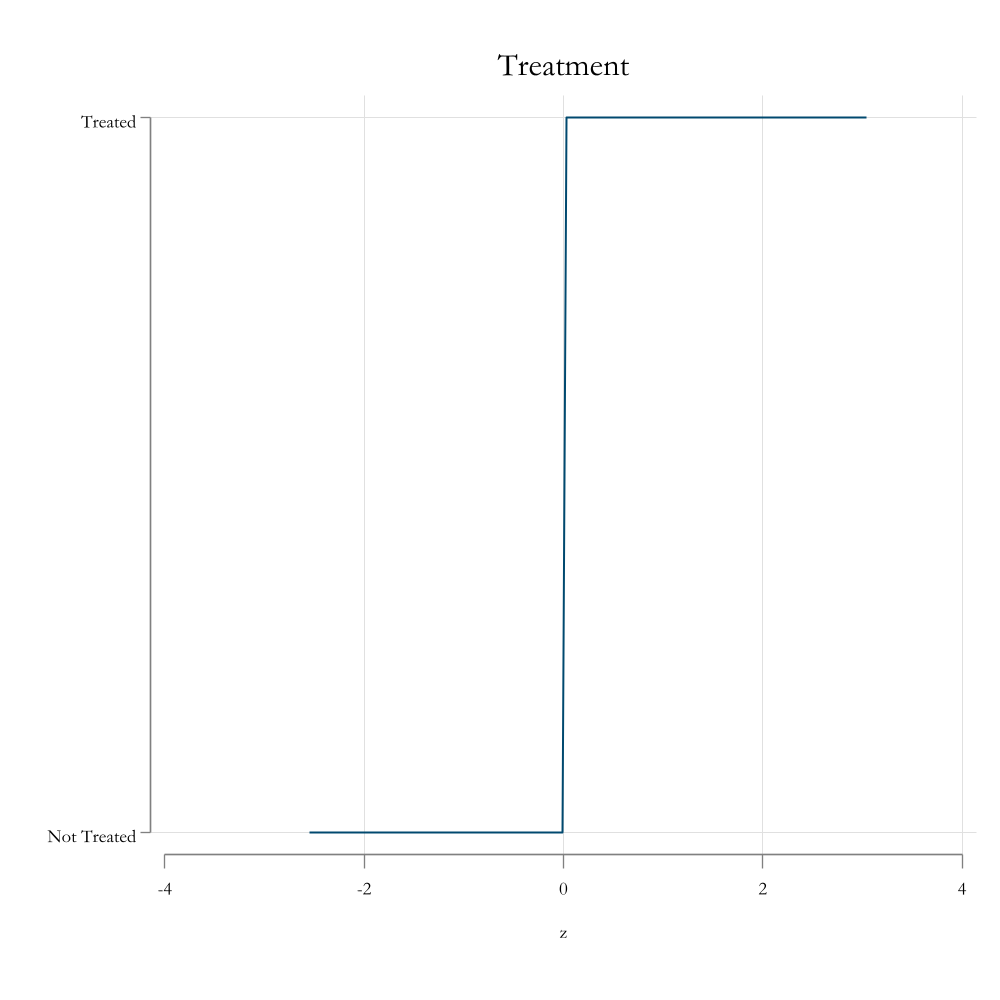
Assignment into treatment is a function of this index only, with a clear threshold for the index to have an impact the treatment.
Those under the Threshold are not treated. Those above are.
This is called a Sharp RDD design.
The threshold should be unique to the Treatment of interest (nothing else happens around that point)
In the College Case, we assume 170 triggers acceptance to School. But if it also triggers Scholarships??
Perhaps the Most important: The score cannot be manipulated
Only then we have true local randomization.
You want the potential outcomes to be smooth functions of Z. (so we do not mix treatment effects with Nonsmooth changes in outcomes)
Sharp RDD
Code
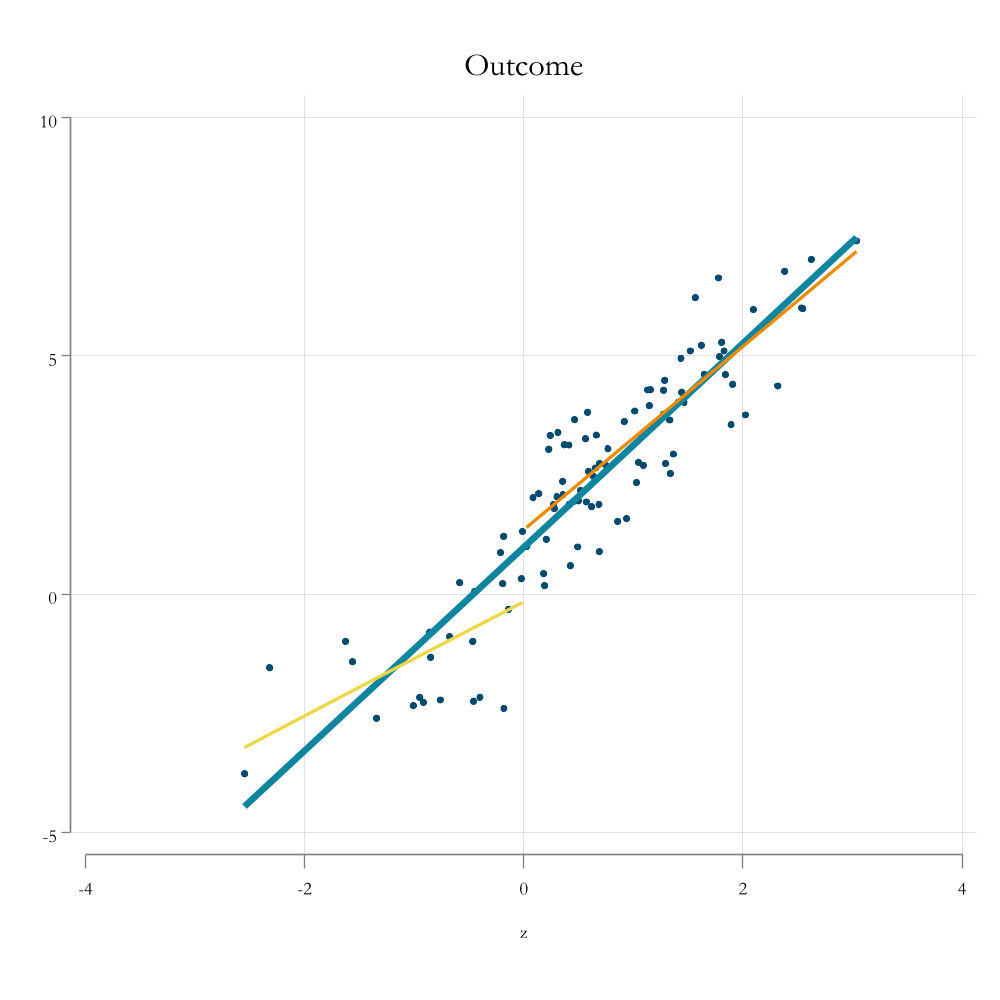
clearssc install synthsetscheme white2color_style baysetseed 1qui:setobs 100gene=rnormal()gen z=runiform()+egen t = z>0geny = 1 + z + e + rnormal() + (z>0)twoline t z, sorttitle("Treatment") ylabel(0 "Not Treated" 1 "Treated") name(m1, replace) ytitle("")graphexport resources\rdd1.png, width(1000) height(1000) replacetwoscattery z, sorttitle("Outcome") pstyle(p1) || lfity z, lw(1) pstyle(p2) /// || lfity z if z<0, lw(0.5) || lfity z if z>0, lw(0.5) , legend(off) name(m2, replace)graphexport resources\rdd2.png, width(1000) height(1000) replace
How it works : p2
Recall that in an RCT (or under randomization) treatment effects are estimated by comparing those treated and those not treated.
\[E(y|D=1)-E(y|D=0)\]
Under SRDD, you can also think about the same experiment, except that we would need to compare individuals AT the theshold.
In this case, the overlapping assumption is violated. So we need to attemp obtaining effects for groups AT the limit when \(Z=c\).
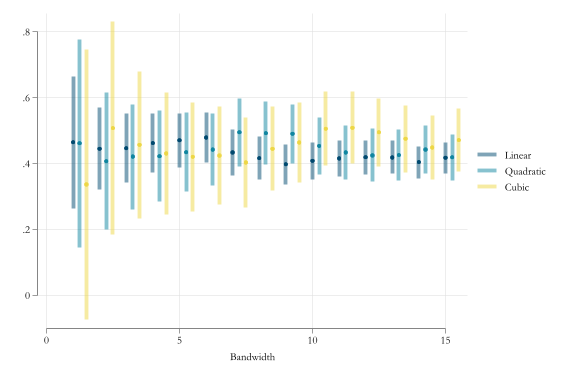
Estimation
The most simple way to proceed is to estimate the model using a parametric approach (OLS)
\[y = a_0 + \delta D_{z>c} + f(z-c) + e\]
The idea here is to identify a “jump” in the outcome (treatment effect) at the point where \(z\) crosses the threshold.
But to identify the jump only, we also need to model the trend observe before and after that threshold (\(f(z-c)\)), which can be modelled as flexible as possible. (this include interactions with the jump)
Alternatively, we could use smaller bandwidths (nonparametric)
Example
Code
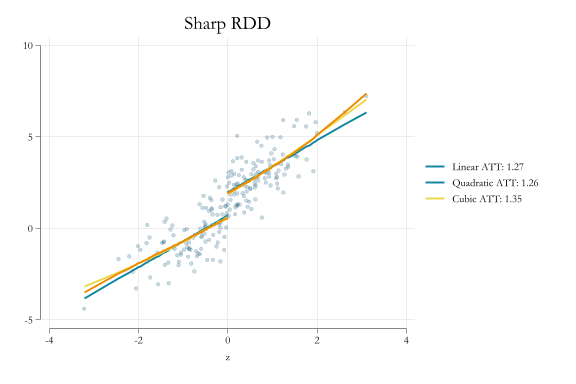
qui: {clearsetseed 1setobs 200gene=rnormal()gen z=runiform()+esum zreplace z=(z-r(mean))/r(sd)gen t = z>0geny = 1 + 0.5*z + e + rnormal() + (z>0)qui:regy t z predict yh1local b1:display %3.2f _b[t]qui:regy t c.z##c.z predict yh2local b2:display %3.2f _b[t]qui:regy t c.z##c.z##c.zpredict yh3local b3:display %3.2f _b[t]sort z}two (scattery z, sorttitle("Sharp RDD") pstyle(p1) color(%20)) /// (line yh1 z if z<0, pstyle(p2) lw(0.5)) (line yh1 z if z>0, pstyle(p2) lw(0.5)) /// (line yh2 z if z<0, pstyle(p3) lw(0.5)) (line yh2 z if z>0, pstyle(p3) lw(0.5)) /// (line yh3 z if z<0, pstyle(p4) lw(0.5)) (line yh3 z if z>0, pstyle(p4) lw(0.5)) , ///legend(order(2 "Linear ATT: `b1'" 3 "Quadratic ATT: `b2'" 4 "Cubic ATT: `b3'")) name(m1, replace)
Example
Code
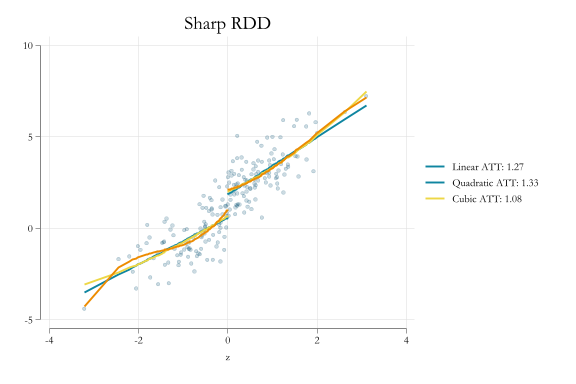
qui: {qui:regy t c.z#t predict yh11local b1:display %3.2f _b[t]qui:regy t (c.z##c.z)#t predict yh21local b2:display %3.2f _b[t]qui:regy t (c.z##c.z##c.z)#tpredict yh31local b3:display %3.2f _b[t]}two (scattery z, sorttitle("Sharp RDD") pstyle(p1) color(%20)) /// (line yh11 z if z<0, pstyle(p2) lw(0.5)) (line yh11 z if z>0, pstyle(p2) lw(0.5)) /// (line yh21 z if z<0, pstyle(p3) lw(0.5)) (line yh21 z if z>0, pstyle(p3) lw(0.5)) /// (line yh31 z if z<0, pstyle(p4) lw(0.5)) (line yh31 z if z>0, pstyle(p4) lw(0.5)) , ///legend(order(2 "Linear ATT: `b1'" 3 "Quadratic ATT: `b2'" 4 "Cubic ATT: `b3'")) name(m2, replace)
Fuzzy RD: Imperfect compliance
While the Idea Scenario happens when there is perfect compliance (above the threshold you are treated), this doesnt happen all the time.
In the education example:
Some people with low grades may be “legacy” or have “contacts” (or took a second exam later) and manage to go to college
Some decided not to go, even after entering to college
Sounds Familiar? (Never takers vs always takers)
When this happens, you can still do RDD, but you need more steps
Fuzzy RD
Estimate the impact of Discontinuity on Treatment
Estimate the impact of Discontinuity on Outcome
Estimate the ratio between (1) and (2)
Sounds Familiar?
Its a kind of wald/IV estimator.
The instrument is the discontinuity
The the endogenous variable is the treament
You still need to estimate the effect as close to the Discontinuity as possible
ivregress may still do most of this for you
Example
Treatment
Outcome
Effect:
Code
qui: gen dz = z>0qui: regy dz c.z##c.z#i.dzlocal b1 = _b[dz]qui: reg t dz c.z##c.z#i.dzlocal b2 = _b[dz]display"There is a " %3.2f `b1'" effect on the outcome"display"and a " %3.2f `b2'" effect on the treatment"display"which imply a LATE of " %3.2f `=`b1'/`b2''
There is a 0.45 effect on the outcome and a 0.44 effect on the treatment which imply a LATE of 1.03
Things to consider
Theoretical:
You need to identify “jumps” caused by a running variable. (depends on knowing how things works)
The potential outcomes have to be smooth functions of the running variable
Empirical:
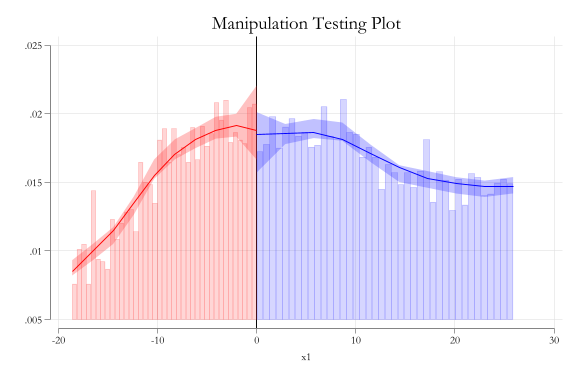
The running variable shouldnt be manipulated. (random)
Implies Assignment rules are not known, are exogenous, and there is no random heaping
Controls should be balanced around the threshold
Testing Empirical Assumptions
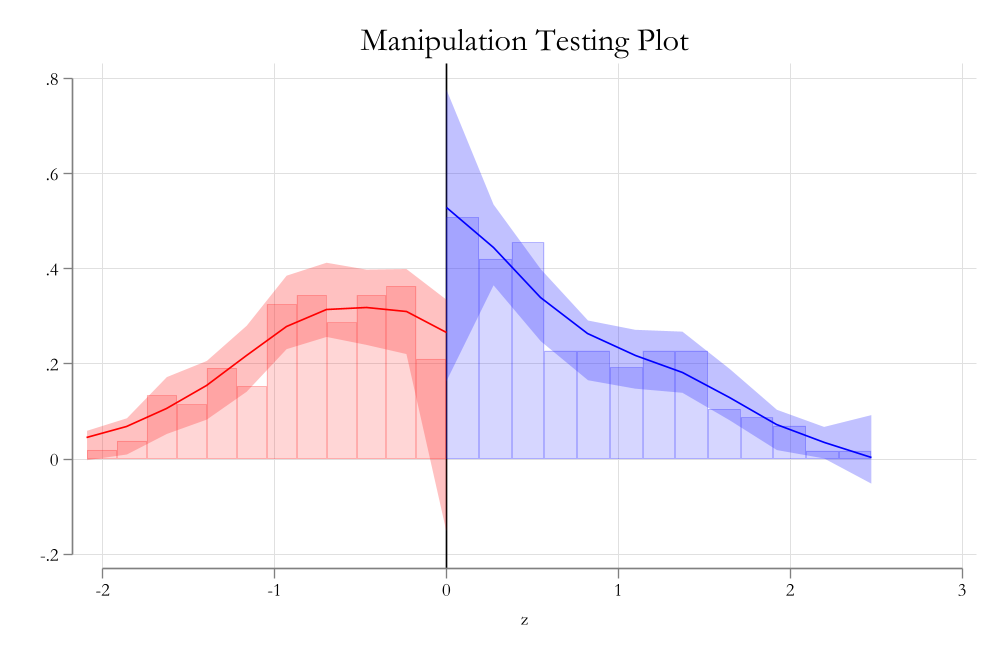
Manipulation of running variable may cause a non-smooth density in the running variable:
If there is no manipulation, you may expect density round threshold to be smooth.
In Stata: ssc install rddensity. In r install.packages(c(‘rdd’,‘rddensity’))
In cases of nonrandom heaping, it may be possible to avoid the problem by restricting the data.
This is an example of measurement error, when individuals may “round-up/down” answers. And may occure near threshold.
This does not necessarily mean there is manipulation.
Possible Solution? Estimate RDD excluding observations around (excluding) threshold.
Covariate balance and Placebo tests
If treatment is locally randomized, then covariates should not be affected by discontinuity.
Alternatively, one could estimate effects on variables you know CANNOT be affected by the treatment
One could also implement a placebo test, checking the impact on a different threholds.
No effect should be observed on the outcome, (but some on the treatment)
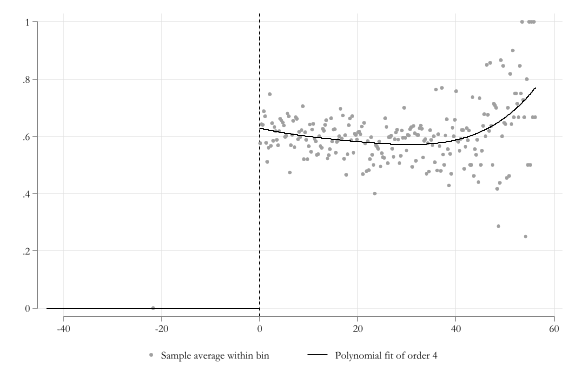
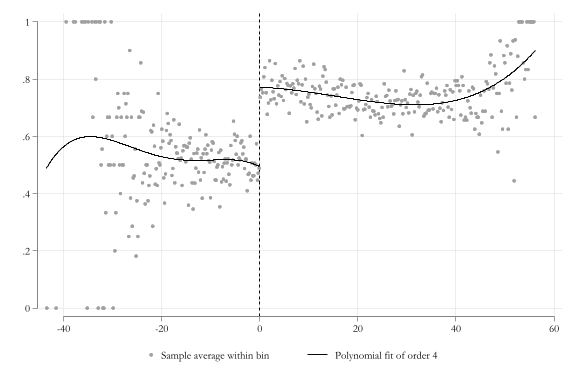
Example
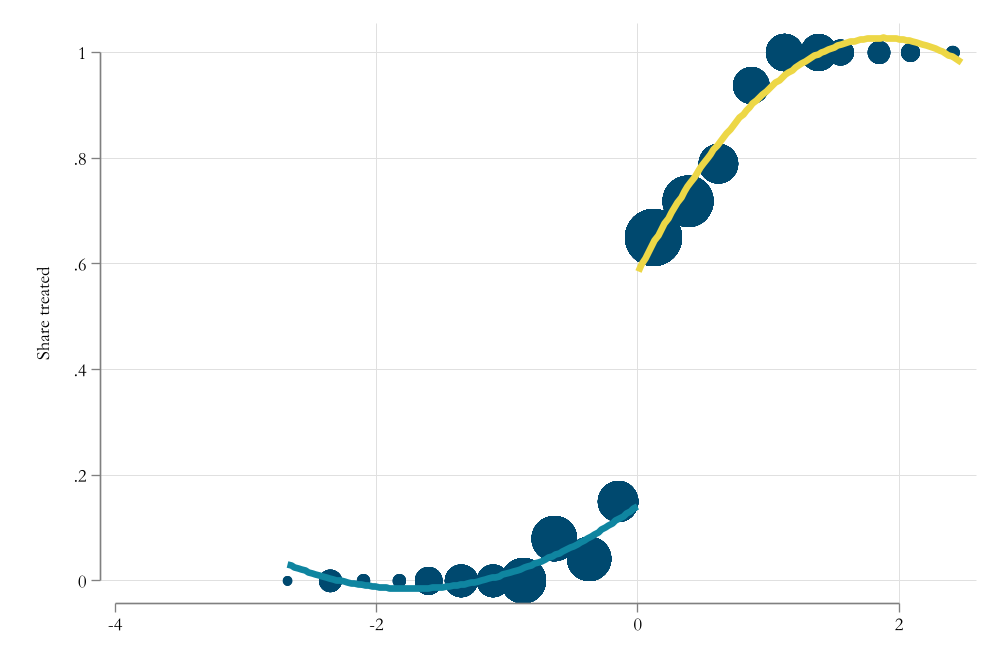
Impact of Scores on Scholarship recipiency
Code
use resources\fuzzy, clearcolor_style bayssc install rdrobustssc install rddensityqui:rdplot d x1, graph_options(legend( pos(6)))
checking rdrobust consistency and verifying not already installed...
all files already exist and are up to date.
checking rddensity consistency and verifying not already installed...
all files already exist and are up to date.
Manipulation test
Code
qui:rddensity x1, plot
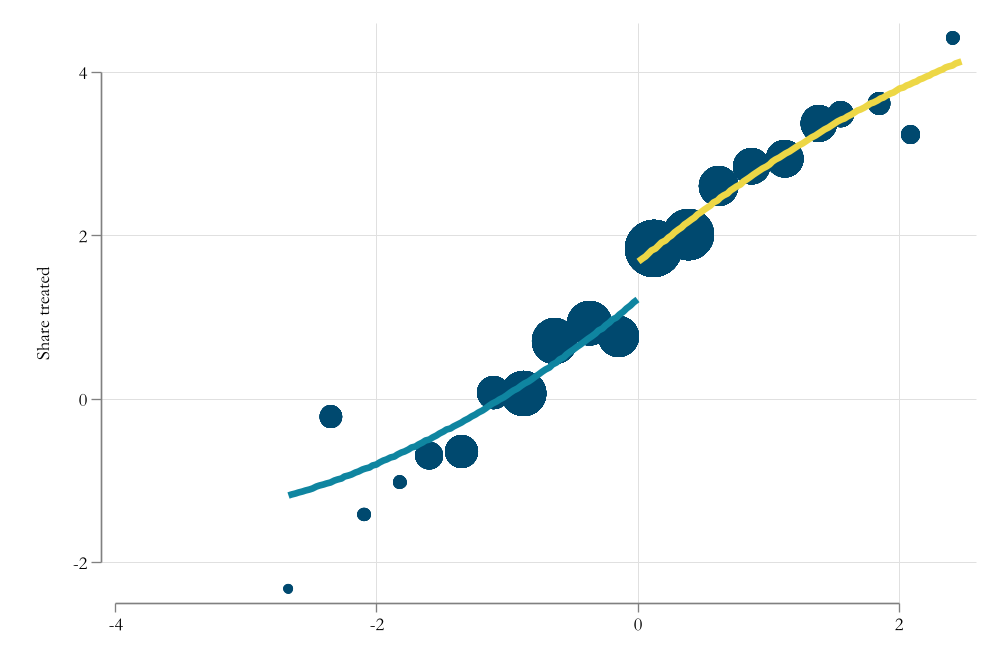
Intention to treat
Impact on Enrollment
Code
qui:rdplot y x1, graph_options(legend( pos(6)))
Estimation of the effect:
Code
gen dx1 = x1>0ivregress 2sls y (d = dx1) c.x1##c.x1#dx1