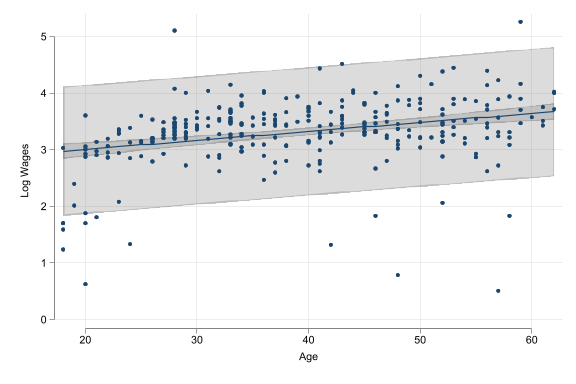
\(\ln(y^E) = \alpha + \beta x_i\)
- log \(y\), level \(x\)
- \(\alpha\) is average \(\ln(y)\) when \(x\) is zero. (Often meaningless.)
- \(\beta\): \(y\) is \(\beta * 100\) percent higher, on average for observations with one unit higher \(x\).
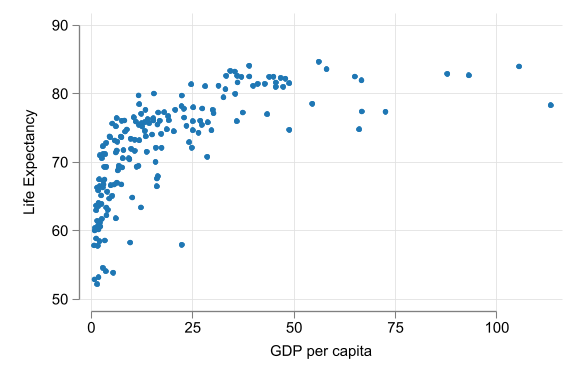
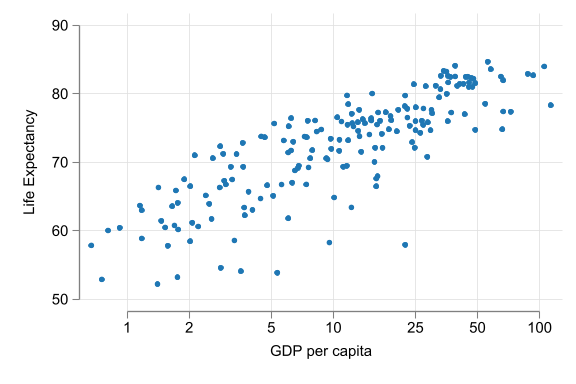
\(y^E = \alpha + \beta\ln(x_i)\)
- level \(y\), log \(x\)
- \(\alpha\) is : average \(y\) when \(\ln(x)\) is zero (and thus \(x\) is one), not very meaningful.
- \(\beta\): \(y\) is \(\beta/100\) units higher, on average, for observations with one percent higher \(x\).
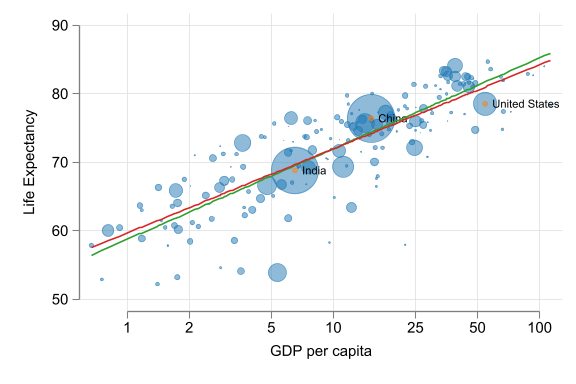
\(\ln(y^E) = \alpha + \beta\ln(x_i)\)
- log \(y\), log \(x\)
- \(\alpha\): is average \(\ln(y)\) when \(\ln(x)\) is zero. (Often meaningless.)
- \(\beta\): \(y\) is \(\beta\) percent higher on average for observations with one percent higher \(x\).
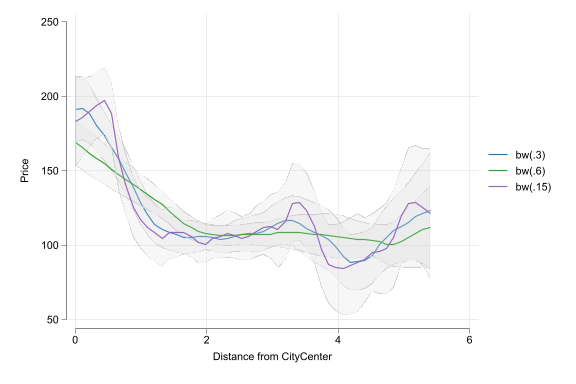
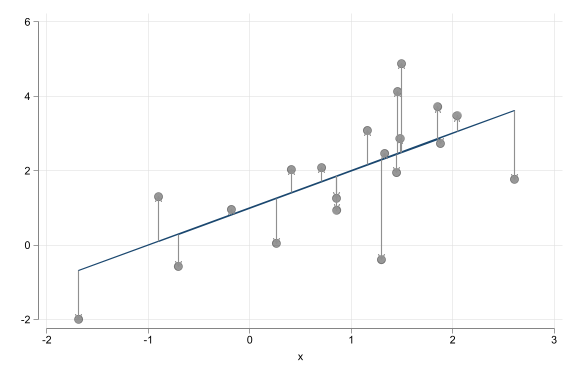
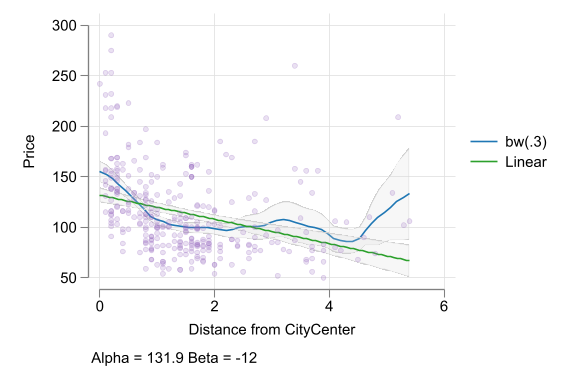
- Precise interpretation is key
- The interpretation of the slope (and the intercept) coefficient(s) differs in each case!
- Often verbal comparison is made about a 10% difference in \(x\) if using level-log or log-log regression.