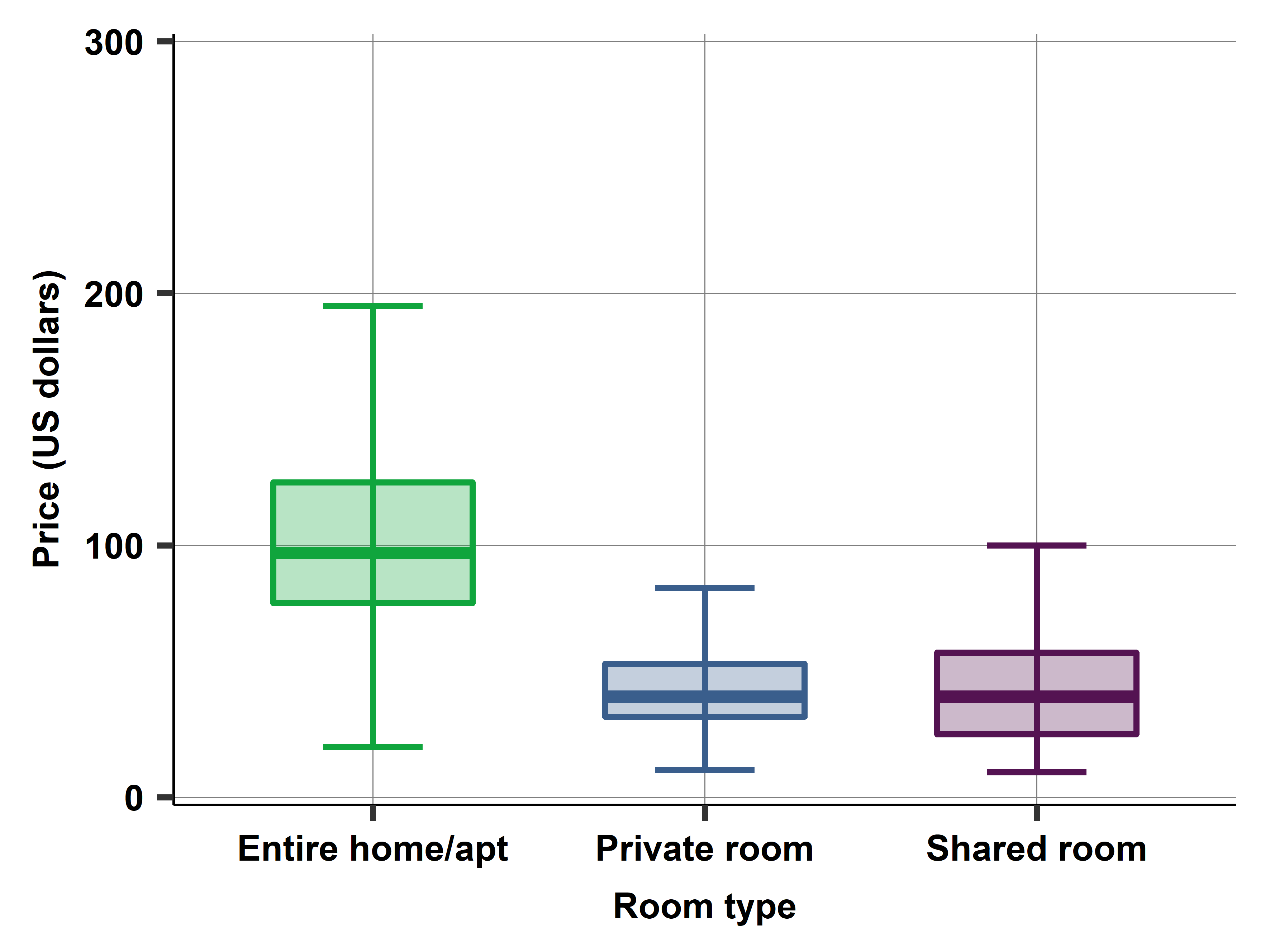
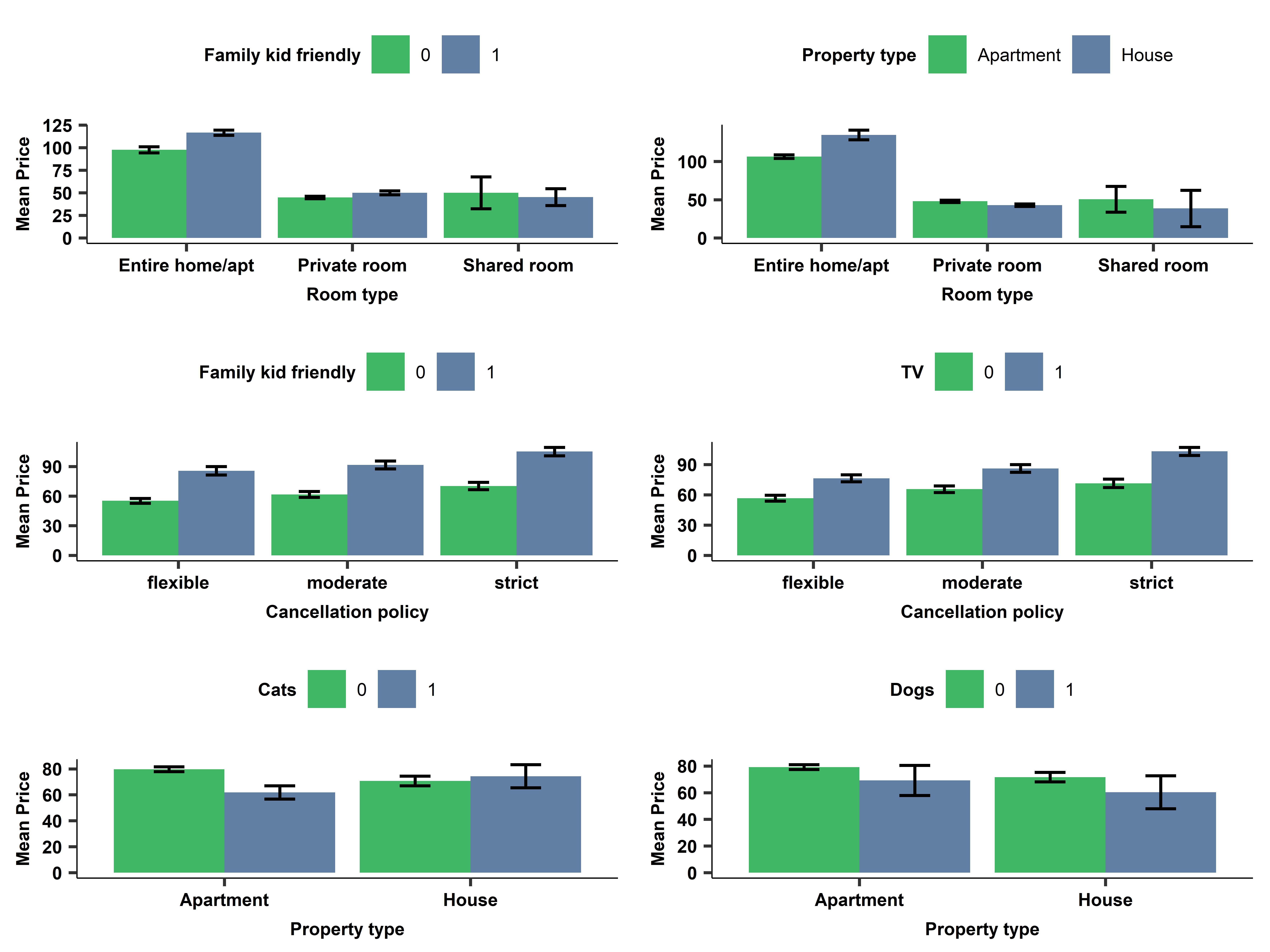
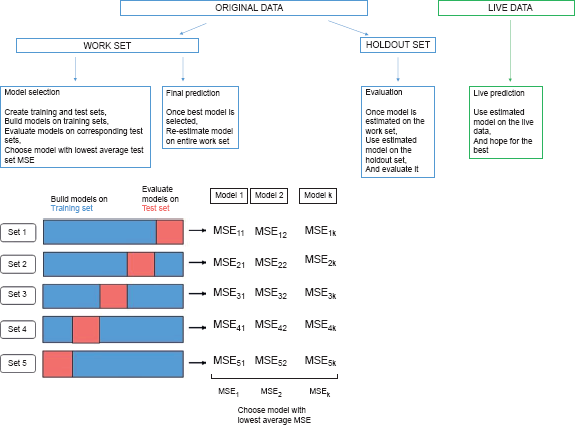
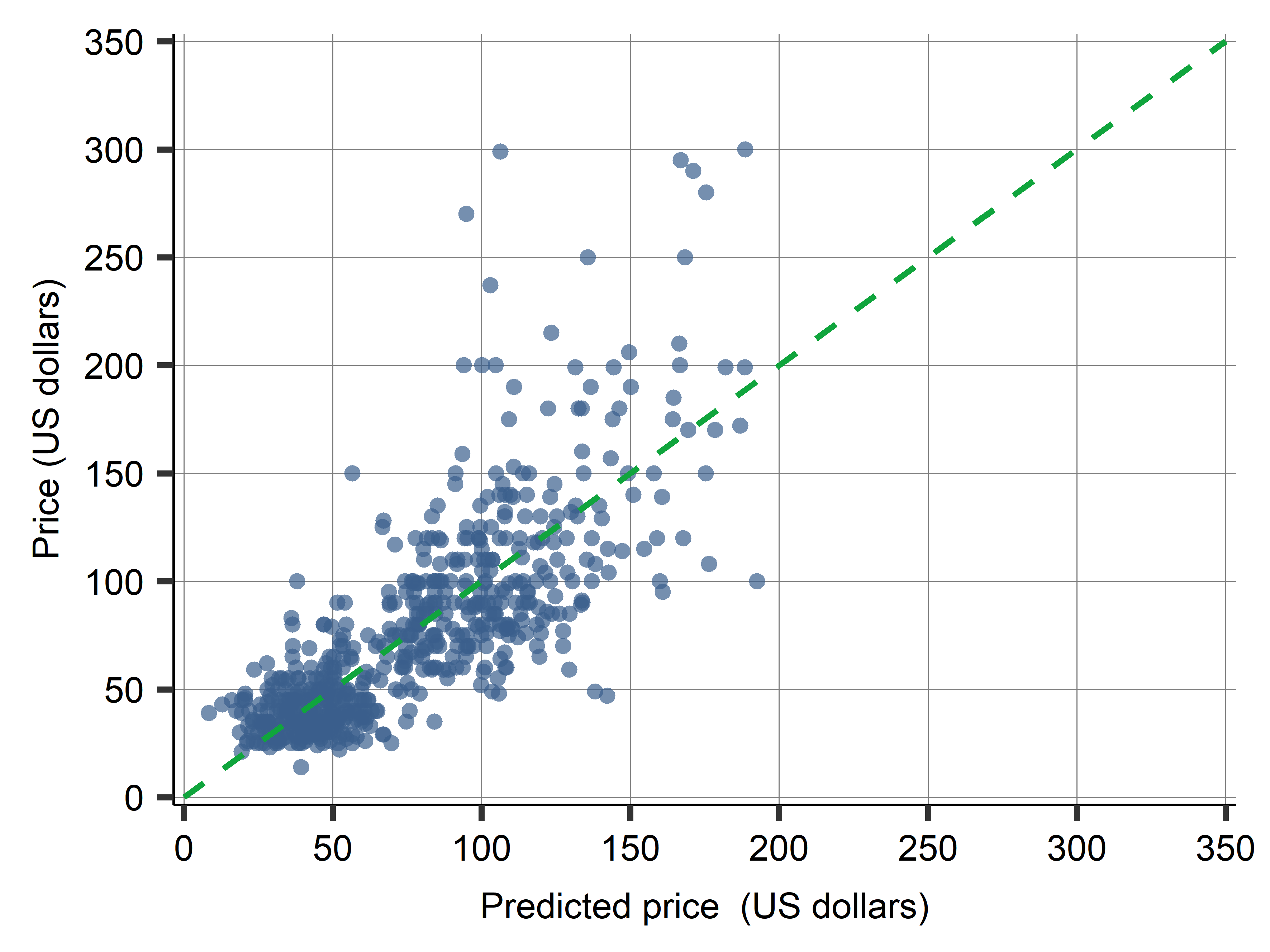
webuse cattaneo2, clear
lasso linear bweight c.mage##c.mage c.fage##c.fage c.mage#c.fage c.fedu##c.medu ///
i.(mmarried mhisp fhisp foreign alcohol msmoke fbaby prenatal1), nolog
ereturn display(Excerpt from Cattaneo (2010) Journal of Econometrics 155: 138–154)
Lasso linear model No. of obs = 4,642
No. of covariates = 26
Selection: Cross-validation No. of CV folds = 10
--------------------------------------------------------------------------
| No. of Out-of- CV mean
| nonzero sample prediction
ID | Description lambda coef. R-squared error
---------+----------------------------------------------------------------
1 | first lambda 107.1305 0 0.0001 334929.8
37 | lambda before 3.761556 10 0.0561 316156.2
* 38 | selected lambda 3.42739 11 0.0561 316154.9
39 | lambda after 3.12291 11 0.0561 316156.8
65 | last lambda .2780062 19 0.0550 316532.1
--------------------------------------------------------------------------
* lambda selected by cross-validation.
------------------------------------------------------------------------------
bweight | Coefficient
-------------+----------------------------------------------------------------
mage | .0026703
|
c.fedu#|
c.medu | .3136748
|
mmarried |
Not married | -140.4633
0.mhisp | -34.00255
0.foreign | 63.71057
0.alcohol | 40.29426
|
msmoke |
0 daily | 167.9734
6–10 daily | -36.54529
11+ daily | -78.1332
|
fbaby |
No | 51.02337
|
prenatal1 |
No | -42.31267
_cons | 3137.903
------------------------------------------------------------------------------