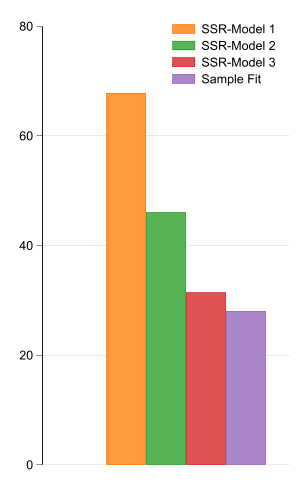As we saw in the previous slides, one of the important steps when doing empirical analysis is to develop a model that describes reality.
This model is quite abstract, as it rarely provides guidance regarding on How should you build your econometric model.
In this chapter, we introduce the first (boring) tool to solve this problem. The simple Regression model or SRL
What is a Simple Regression Model (SRM) ?
A Simple regression model is known as such because it aims to capture the relationship between two variables.
It does not mean it ignores other factors, but rather, bundles them together as part of a Bag of Holding or error. In its most flexible setup, a simple regression model can be written as:
\[y = f(x,u)
\]
This model simply says that there is some relationship between:
\(y\), your outcome, dependent, explained, response, variable
and \(x\), your independent, explanatory, regression, variable
whereas everything else not considered is assumed to be part of the unobserved \(u\).
From Abstract to Concrete
A good reason why one should start thinking about the model as shown earlier is to acknowledge that we Do not know the functional form between \(x\) and \(y\).
Further, we don’t even know how \(u\) interacts with \(x\).
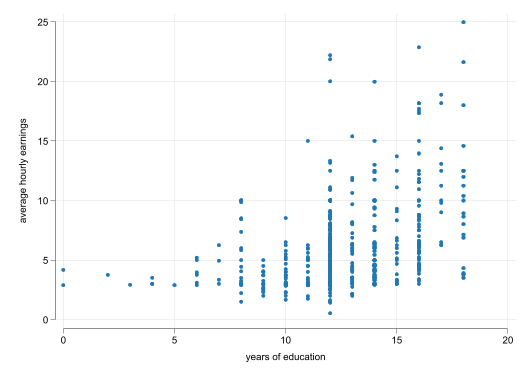
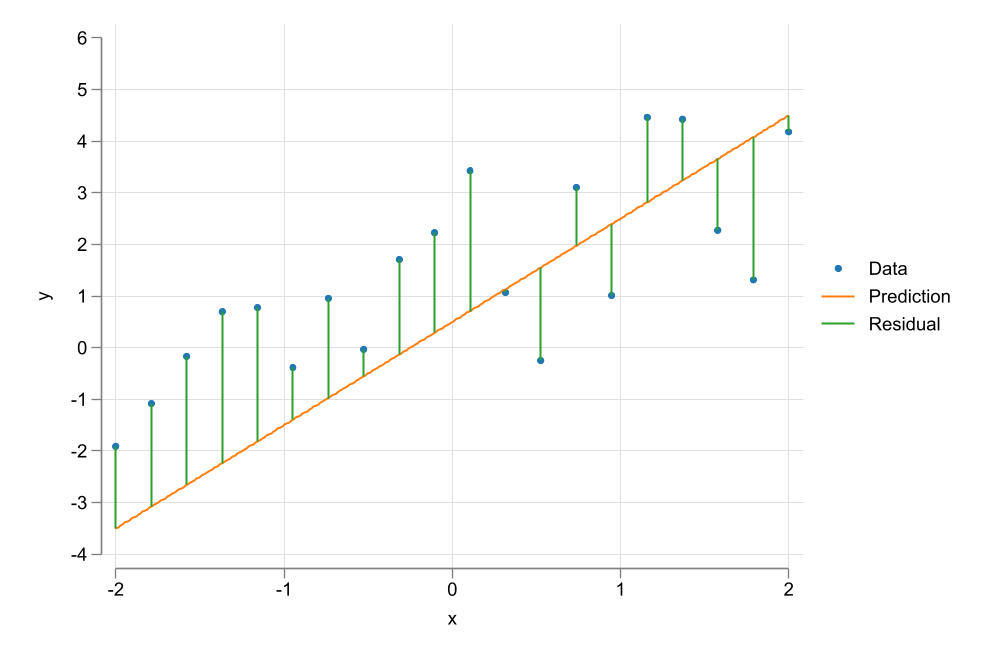
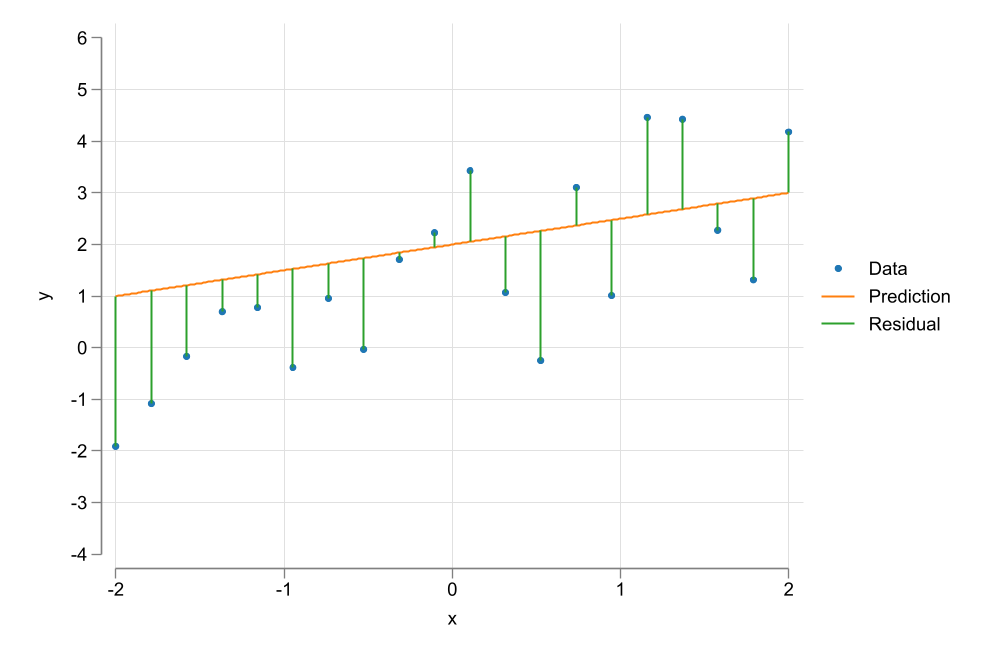
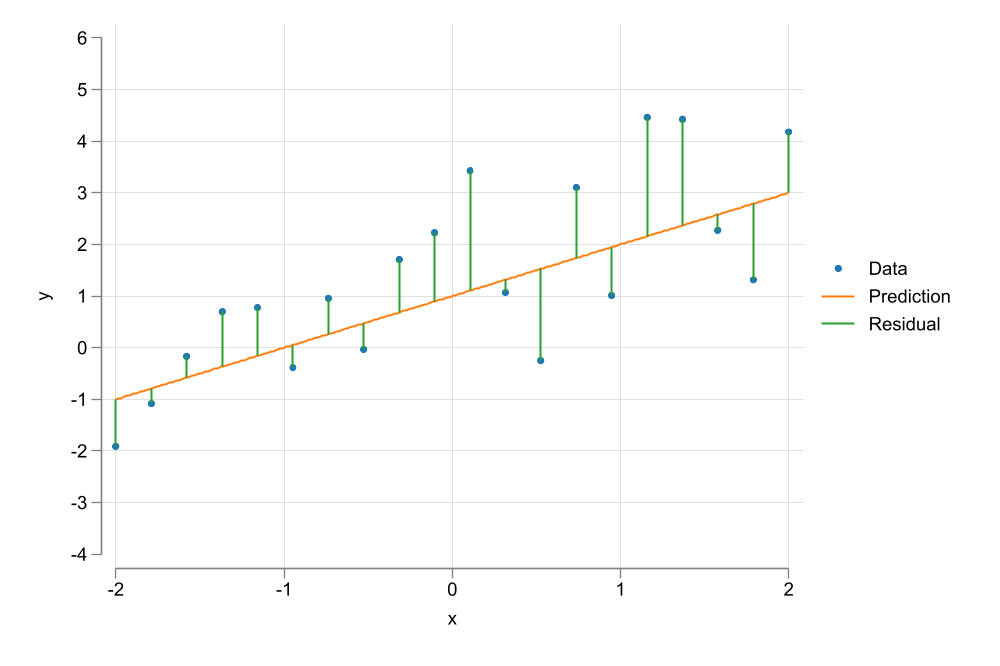
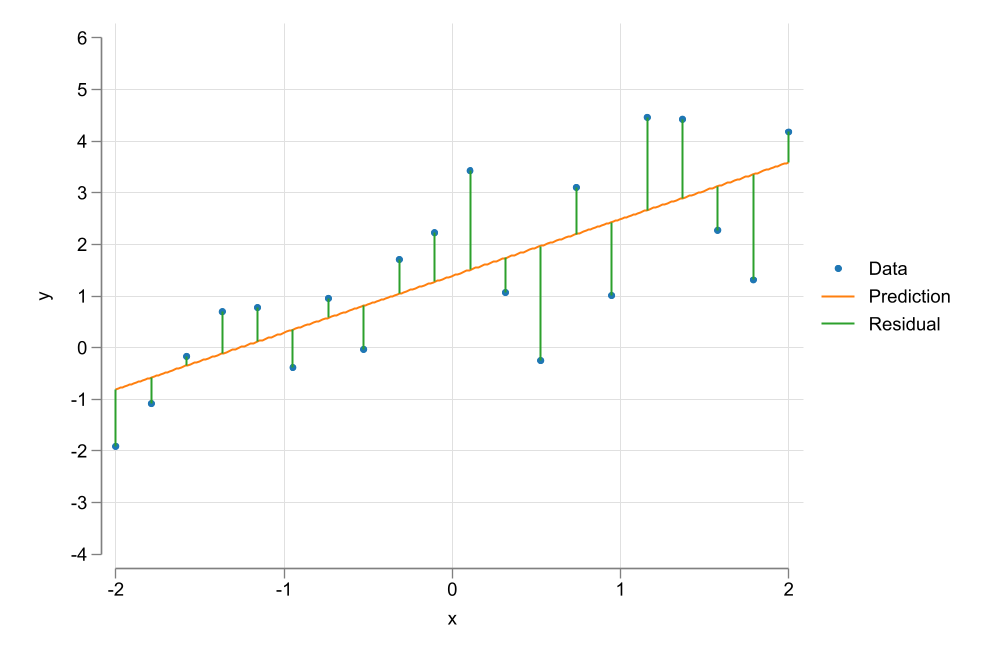
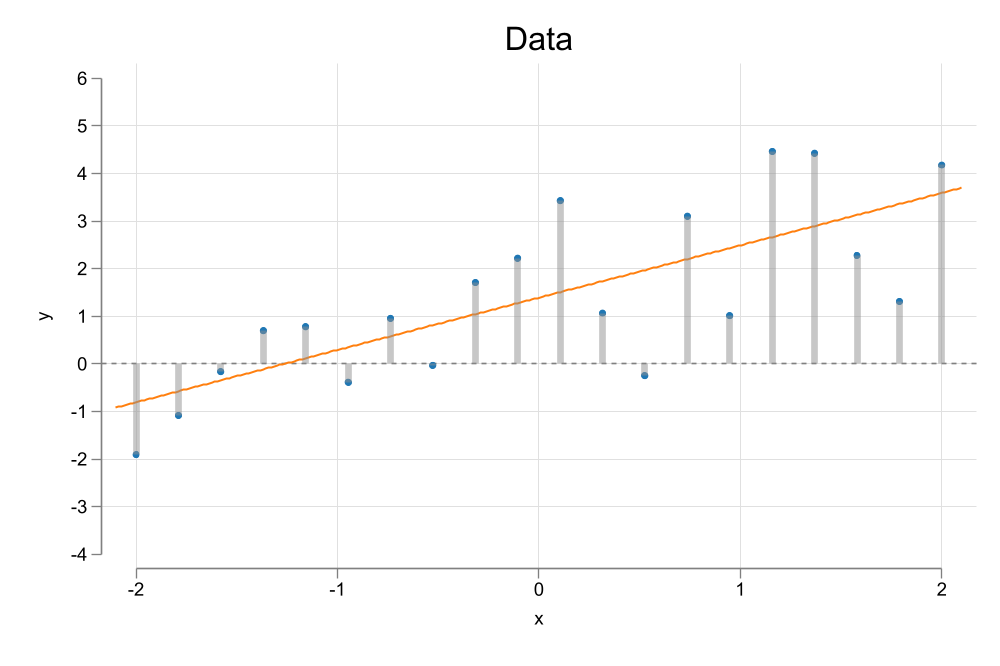
This brings us to the first step one should do (almost always) when analyzing data…Create a plot to see if there is any relationship in the data
Simple Scatter 1
Code
** To download all Wooldrige Filesqui: ssc install frause, replace** for some additional color schemesqui: ssc install color_stylesetscheme white2color_style tableau** Loads file wage1frause wage1, clearscatter wage educ
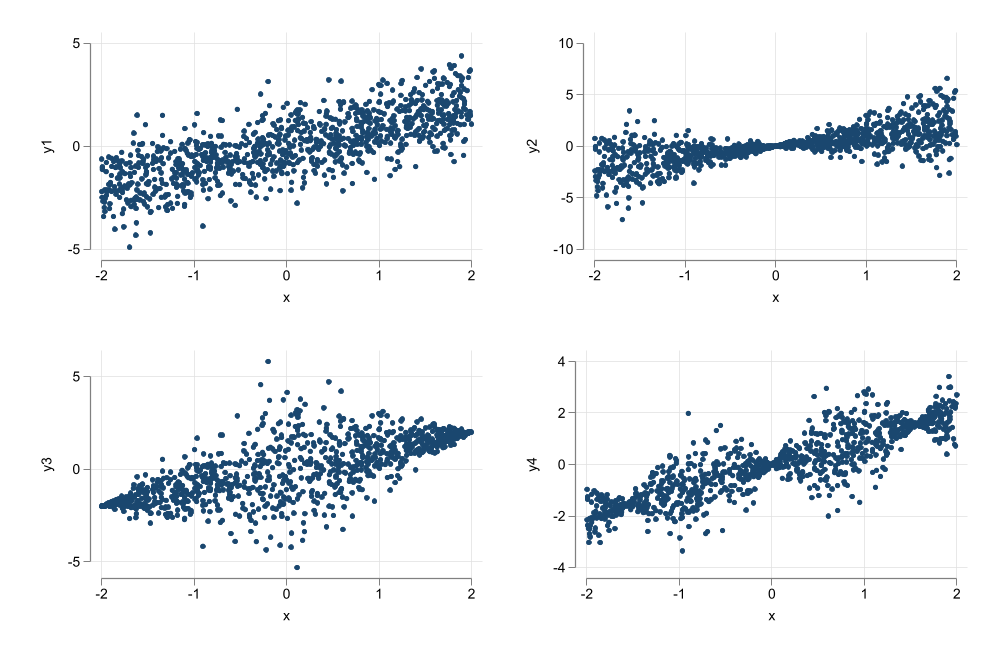
We observe a positive relationship between Wages and years of education
This relationship does not seem to be linear
Simple Scatter 2
Even more Concrete
This first “model” provides little guidance for the modeling itself.
The Simple Linear Regression Model corrects for that, establishing a specific relationship between the variables of interest and the error: \[y = \beta_0 + \beta_1 x + u\]
This model has a lot packed in.
It imposes a relationship between \(y\) and \(x\) (linear)
And addresses the fact that there could be other factors not considered \(u\). Impossing the assumption they are additive errors.
It also assumes the population relationships: \[E(y|x) = \beta_0 + \beta_1 x\]
What can we learn from it?
\[E(y|x) = \beta_0 + \beta_1 x\]
This is your Population Regresson function. To interpret it, we need to assume \(u\) is fixed (ceteris paribus). This implies that \[E(u|x)=c=0\]
Which says that the errors are mean independent of \(x\). Thus, for all practical purposes, when \(x\) changes, we will assume \(u\) is as good as fixed.
Under these conditions, we can interpret the coefficients:
\(\beta_0\) is the constant, or expected outcome when \(x=0\).
\(\beta_1\) is the slope of \(x\), or the expected change in \(y\) when \(x\) changes in 1 unit:
\[\Delta y = \beta_1 \Delta x \rightarrow \frac{\Delta y}{\Delta x} = \beta_1
\]
Example
Soybean and Yield Fertilizer:
\[yield = \beta_0 + \beta_1 fertilizer + u\]
\(\beta_1\) Effect of Fertilizer (an additional dosage) on Soybean Yield
Simple wage equation
\[wage = \beta_0 + \beta_1 educ + u
\]
\(\beta_1\) Change in wages given an additional year of education.
Deriving Coefficients: Ordinary Least Squares - OLS
There are an infinite number of candiates for \(\beta_0 \& \beta_1\).
OLS, is one of the multiple methods that allows us to estimate the coefficients of a SLRM1.
The goal is to Choose parameters \(\beta={\beta_0,\beta_1}\) that “minimizes” the Squared of the residuals.
In other words, OLS aims to maximize Explantion power by minimizing errors.
***Variables Description***
Variable Storage Display Value
name type format label Variable label
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
salary int %9.0g 1990 salary, thousands $
roe float %9.0g return on equity, 88-90 avg
***Summary Statistics***
Variable | Obs Mean Std. dev. Min Max
-------------+---------------------------------------------------------
salary | 209 1281.12 1372.345 223 14822
roe | 209 17.18421 8.518509 .5 56.3
***Simple Regression***
Source | SS df MS Number of obs = 209
-------------+---------------------------------- F(1, 207) = 2.77
Model | 5166419.04 1 5166419.04 Prob > F = 0.0978
Residual | 386566563 207 1867471.32 R-squared = 0.0132
-------------+---------------------------------- Adj R-squared = 0.0084
Total | 391732982 208 1883331.64 Root MSE = 1366.6
------------------------------------------------------------------------------
salary | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
roe | 18.50119 11.12325 1.66 0.098 -3.428196 40.43057
_cons | 963.1913 213.2403 4.52 0.000 542.7902 1383.592
------------------------------------------------------------------------------
Now, Changing scales has no effect on \(R^2\), nor the coefficient to Standard error ratio (\(t-stat\))
It could allow for easier interpretation of the results.
gen saldol=salary*1000gen roedec=roe / 100qui: reg salary roeest sto m1qui: reg saldol roeest sto m2qui: reg salary roedecest sto m3esttab m1 m2 m3, se r2
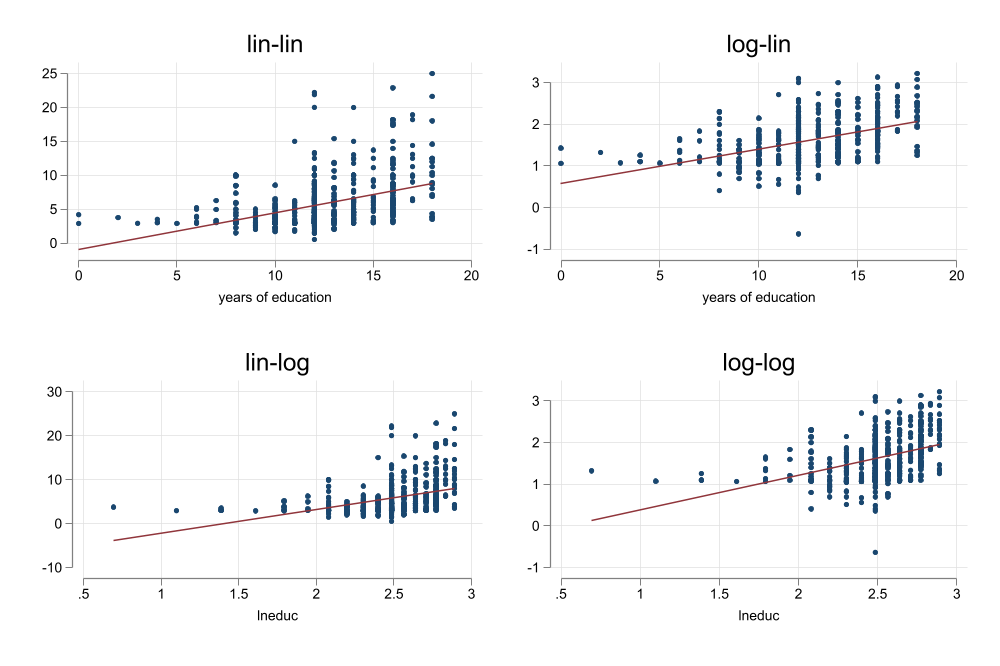
An additional year of education
1. Increases hourly wages in 54cnts
2. Increases hourly wages in 8.3%
3. A 1% increase in years of education (about 1.5months) increases wages in 5.3cnts
4. A 1% increase in years of education would increase wages in 0.82%.
Expanding on SLRM: Using Dummies
A SLRM can also be done using Dummy variables. (Those that take only two values: 0 or 1)
This type of modeling may be observed when evaluating programs (Were you treated?(Tr=1) or not (Tr=0))
And can be used to Easily compare means across two groups:
\[wage = \beta_0 + \beta_1 female + e
\]
In this particular case, both \(\beta_0 \& \beta_1\) have clear interpretation:
In most Software, you need to either Create the new variable explicitly, or use internal code to make it for you:
frause wage1, clear** verify Codingssc install fre, replacefre female** create your owngen is_male = female==0** Regression using Newly created variablereg wage is_male** Regression using Stata "factor notation"reg wage i.female
checking fre consistency and verifying not already installed...
all files already exist and are up to date.
female -- =1 if female
-----------------------------------------------------------
| Freq. Percent Valid Cum.
--------------+--------------------------------------------
Valid 0 | 274 52.09 52.09 52.09
1 | 252 47.91 47.91 100.00
Total | 526 100.00 100.00
-----------------------------------------------------------
Source | SS df MS Number of obs = 526
-------------+---------------------------------- F(1, 524) = 68.54
Model | 828.220467 1 828.220467 Prob > F = 0.0000
Residual | 6332.19382 524 12.0843394 R-squared = 0.1157
-------------+---------------------------------- Adj R-squared = 0.1140
Total | 7160.41429 525 13.6388844 Root MSE = 3.4763
------------------------------------------------------------------------------
wage | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
is_male | 2.51183 .3034092 8.28 0.000 1.915782 3.107878
_cons | 4.587659 .2189834 20.95 0.000 4.157466 5.017852
------------------------------------------------------------------------------
Source | SS df MS Number of obs = 526
-------------+---------------------------------- F(1, 524) = 68.54
Model | 828.220467 1 828.220467 Prob > F = 0.0000
Residual | 6332.19382 524 12.0843394 R-squared = 0.1157
-------------+---------------------------------- Adj R-squared = 0.1140
Total | 7160.41429 525 13.6388844 Root MSE = 3.4763
------------------------------------------------------------------------------
wage | Coefficient Std. err. t P>|t| [95% conf. interval]
-------------+----------------------------------------------------------------
1.female | -2.51183 .3034092 -8.28 0.000 -3.107878 -1.915782
_cons | 7.099489 .2100082 33.81 0.000 6.686928 7.51205
------------------------------------------------------------------------------
if the Dummy is a treatment, and Assumption 4 Holds, then you can use this to estimate Average Treatment Effects (ATE) aka Average Casual Effects. (Usually requires randomization)