Code
** Montecarlo Simulation
set linesize 255
clear
set seed 10101
set obs 1000
qui:mata:
k = 1000; n=1000
b1=bc = b = J(k,2,0)
for(i=1;i<=k;i++){
e = rchi2(n,1,2):-2
e1 = rchi2(n,1,2):-2
z = rchi2(n,1,2):-2,J(n,1,1)
x = rchi2(n,1,2):-2:+z[,1]:+e ,J(n,1,1)
x1 = rchi2(n,1,2):-2:+z[,1]:+e1,J(n,1,1)
y = 1:+x[,1]:+e
y1 = 1:+x[,1]:+e1
xx = cross(x,x)
b[i,] = (invsym(xx)*cross(x,y))'
bc[i,] = (invsym(cross(z,x))*cross(z,y))'
b1[i,] = (invsym(xx)*cross(x,y1))'
}
end
getmata bb*=b
getmata bc*=bc
getmata b_*=b1
set scheme white2
color_style tableau
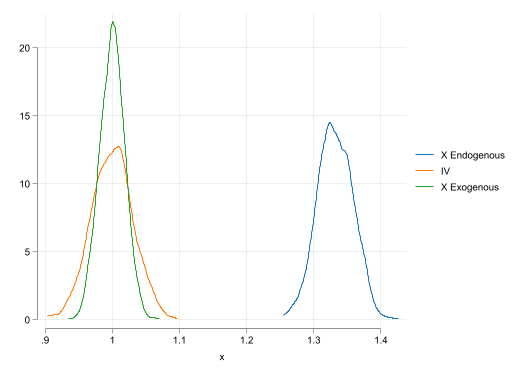
two kdensity bb1 || kdensity bc1 || kdensity b_1, ///
legend(order(1 "X Endogenous" 2 "IV" 3 "X Exogenous"))