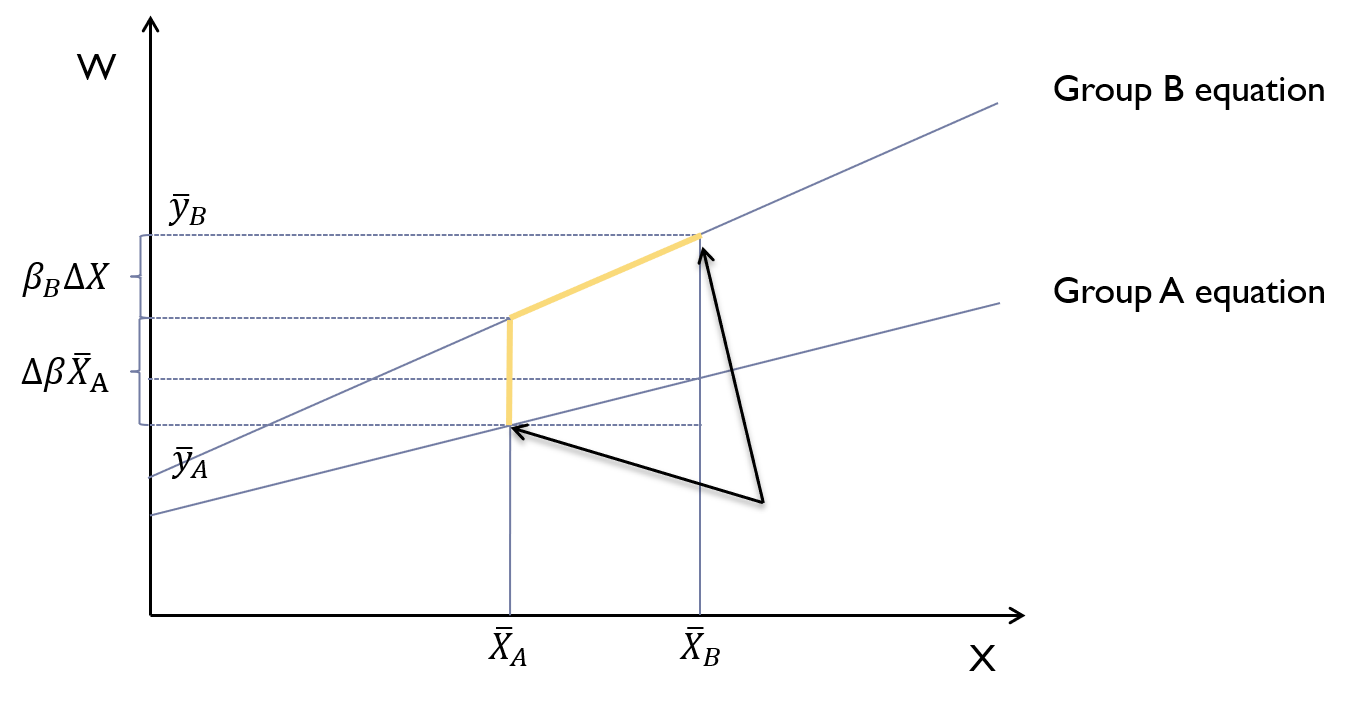
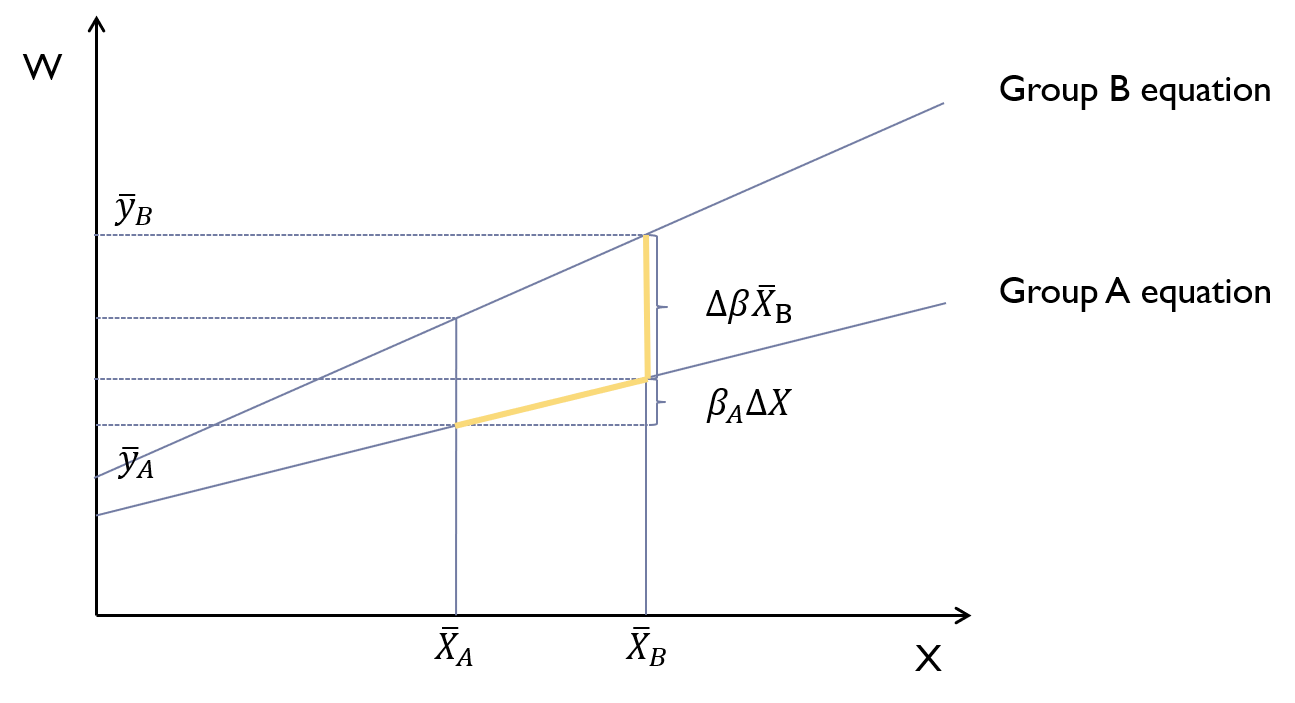
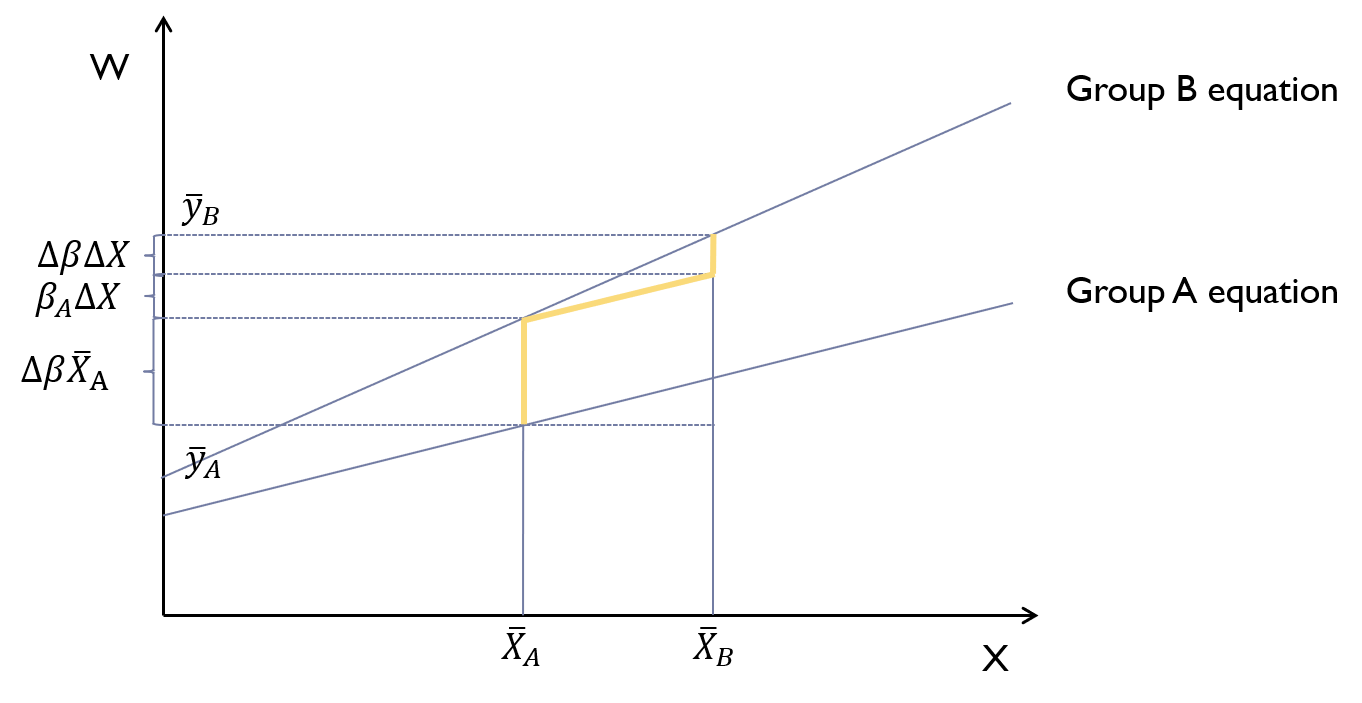
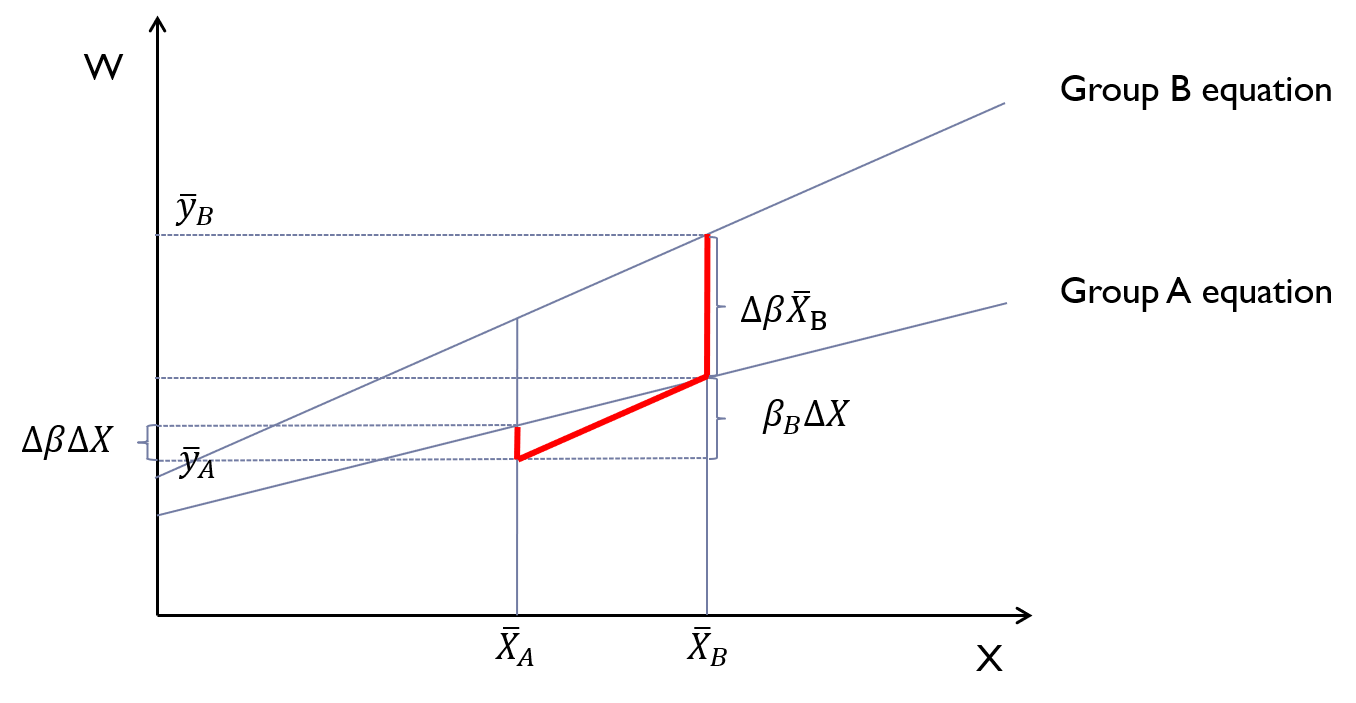
Code
checking oaxaca consistency and verifying not already installed...
all files already exist and are up to date.
----------------------------------------------------------------------
(1) (2)
bw_Xm Xm_bw
----------------------------------------------------------------------
overall
group_1 3.440*** (196.70) 3.440*** (196.70)
group_2 3.267*** (149.41) 3.267*** (149.41)
difference 0.173*** (6.20) 0.173*** (6.20)
explained 0.0446* (2.50) 0.0222 (1.28)
unexplained 0.129*** (4.63) 0.151*** (5.69)
----------------------------------------------------------------------
explained
educ 0.0496*** (4.15) 0.0315*** (4.09)
exper 0.0150 (1.92) -0.00960* (-2.08)
age -0.00691 (-1.32) -0.0185 (-1.46)
married -0.0132* (-2.36) 0.0189*** (3.40)
----------------------------------------------------------------------
unexplained
educ -0.369** (-2.96) -0.351** (-2.96)
exper -0.179** (-3.17) -0.154** (-3.18)
age 0.521*** (4.00) 0.533*** (4.00)
married 0.153*** (5.62) 0.121*** (5.54)
_cons 0.00234 (0.02) 0.00234 (0.02)
----------------------------------------------------------------------
N 1434 1434
----------------------------------------------------------------------
t statistics in parentheses
* p<0.05, ** p<0.01, *** p<0.001